




1. Introduction
Vietnamese is a native language spoken by almost one hundred million people in the world. Alexandre de Rhodes, who came to evangelize in Vietnam since the early eighteenth century, developed this national language. We found the Vietnamese language interesting to discover and we decided to start with its phonology. In the study of Nguyen & Dutta (2017), the adaptation of French consonant clusters in Vietnamese phonology based on the framework of Optimality Theory (OT) was explored. The findings of this paper found that deletion was more in favour of choice to avoid clusters in the coda position. This strategy of adaptation is similar to what has been found in Ashok & Dutta (2021). By contrast, both the epenthesis strategy and deletion strategy were used to repair the onset clusters. In this paper, we would like to revisit the Vietnamese consonants, Vietnamese vowels and French phonology for analytical convenience. Furthermore, we are going to present the phonological changes at the segmental level, using the same theory, OT. We investigated the adaptation of French consonant segments in the onset position (initial sound articulation of the Vietnamese consonants) and the adaptation of French consonant segments in coda position (final sound articulation of the Vietnamese consonants) into the Vietnamese language. Furthermore, we looked into the adaptation of foreign simplex codas in word—final positions. It was interesting to see how the final sound of a Vietnamese word was changed when it was adapted by French. Furthermore, the adaptation of French vowels into the Vietnamese language was also investigated. This was done to see how French vowel adaptation changed the way Vietnamese vowels were pronounced. In the following sections, we are going to present our work on the topic.
2. Literature Review
When discussing the Vietnamese language, we must examine its foreign quality. Most of the foreign languages imported into Vietnamese have a connection with the history of the country. The three dominating languages on Vietnamese are Mandarin Chinese during the Chinese rule from 111B.C to 938 A.D, French during the French colonization from 1858 to 1945 and English from the nineteenth century until the present (Nguyen 2007).
In the beginning of the 18th century, the French started to colonize Vietnam, and this colonization lasted almost a hundred years. A bilingual linguistic society began to appear in Vietnam after the French arrived. In order to rule Vietnam easier, the French implemented a policy which attempted to spread the French language across this country in different ways. Many French-Vietnamese schools were opened and French along with Vietnamese was used in the media. Code mixing and code switching became frequent in conversations among the Vietnamese during this time. This linguistic situation led to the formation of a pidgin French widely used in Vietnam during the French colonization, but it disappeared when the French left (Crystal 2010). As Nguyen (2007) put it, some 3,000 Vietnamese words were borrowed from French, albeit not being broadly used in the present Vietnamese community. French loans borrowed during French colonization involved terms related to fashion, units of measurement, construction, entertainment, transportation, machinery and food.
A very good source, Barker (1969), who had a great contribution to listing dozens of French loanwords in Vietnamese. The author also showed a list of the phonemic system of French and a list of the phonemic system of Vietnamese. These two lists are very necessary for the comparison of the system. He, moreover, mentioned the adoption of the initial position of the sound /b-/ in French to a lack of the initial position sound /p-/ in Vietnamese such as a French word pupe for a Vietnamese word bup-be. Other generalizations of sound changes in Vietnamese due to French loanwords were also discussed in his article.
Many researchers have paid attention to the investigation of segmental adaptation in loanword phonology in many languages. The results have disclosed that the degree of segmental adaptation generally shows an inclination of sound changes. When the foreign sound input is adapted in the native language, it causes a change of sound. That means when the foreign input contains a non-native segment, this segment is replaced with the closest sound in the native language.
Arsenault (2008) examines the adaptation of English alveolar stops in Telugu and Hindi and finds that English alveolar stops are always adapted as retroflex and never as dental. For example, the English words “taxi” and “soda” are adapted as /ʈæksi/ and /soɖa/, respectively, in Hindi. Similarly, in Telugu, the English words “party” and “candy” are adapted as /pa:ʈi/ and /kæɳɖi/, respectively. He explains that retroflex stops in these two languages are contrastively specified as [apical] in the host languages, while dentals are underspecified for coronal features and are redundantly laminal. This adaptation is based on perception. Both [apical] and retroflex sounds have similar spectral bursts in their articulation. Thus, the speakers of Telugu and Hindi are sensitive to these primary cues and thus associate these cues with retroflex articulations.
Chang (2009) studies English loanword adaptation in Burmese and proposes that where an English word contains a segment which is absent from the Burmese inventory, the illicit segment is generally replaced by the closest correspondent from the native phonology. For example, the voiceless labiodental fricative /f/ is almost invariably substituted by the voiceless aspirated bilabial stop /pʰ/.
In Thai, the English segment /v/ is mapped to /w/ in the onset and to /p/ in the coda (Kenstowicz & Suchato 2006). In Jahai, Malay /k/ is generally adapted as /k/, but as /ʔ/ word-finally, reflecting the allophonic realization of /k/ in the Malay input (Burenhult 2001). In Fon, French /r/ is mapped to /úl/ word-initially, to /l/ in non-initial prevocalic position, and is deleted in pre-consonantal or word-final position (Gbéto 2000, as discussed in Kenstowicz 2007). In Korean, English /s/ is adapted as /s′/ in prevocalic or word-final position and as /s/ elsewhere (Davis & Cho 2006, Kang 2010). In 1930s Korean, English voiced stops /b, d, g/ were mapped to tense stops /p′, t′, k′/ word-initially and as lax stops /p, t, k/ elsewhere (Kang 2011).
Uffmann (2006) studies vowel epenthesis in loanwords in the languages of Shona, Sranan, Samoan and Kinyarwanda and his analysis shows that the quality of the epenthetic vowel results from three strategies, which are default insertion, vowel harmony and consonantal spreading. He concludes that the factors which constrain the different strategies were found to be identical across languages; however, spreading is constrained by the markedness of the spreading feature: high and front vowels are more likely to spread than low vowels, and coronal and labial consonants are more likely to spread than dorsal consonants, which hardly ever seem to spread. In addition, non-local spreading is constrained by the sonority of the intervening segment: the less sonorous it is, the more likely vowel harmony is to apply. Default insertion was only found to apply when spreading exceeded a certain language-dependent markedness threshold.
OT was introduced by Prince & Smolensky (1993) and McCarthy & Prince (1993). OT is a general theory of grammar, rather than one of phonology. However, the impact of OT in the area of phonology has been significant. The constraint-based theory of this approach has had a rather strong influence on the linguistic studies in general. The theory introduces constraints and constraint ranking instead of rules or rule ordering. The constraints behave in a conflicting manner because satisfying one constraint will lead to violation of the other. Hence, they have to be ranked in order.
Consequently, Kager (1999) suggests some assumptions made about constraints in OT which are presented in Table 1 below.
According to Kager (1999), OT recognizes two types of constraints: markedness constraints and faithfulness constraints. Each constraint evaluates one specific aspect of output markedness or faithfulness. Markedness constraints and faithfulness constraints are shown in Table 2 below.
| Examples of Markedness Constraints | Examples of Faithfulness Constraints |
|---|---|
| - Vowels must not be nasal (*V NASAL). - Syllables must not have codas (NO CODA). - Syllables must have onsets (ONSET). - Obstruent must be voiced (*VD OBS). - Sonorants must be voiced (VD SON). |
- The output must preserve all segments present in the input (DEP-IO). - Elements adjacent in the input must be adjacent in the output (CONTIGUITY). - Input segments must have counterparts in the output (MAX-IO). - The specification for place of articulation of an input segment must be preserved in its output correspondent (IDENT-IO [PLACE]) (Kar 2010). |
Examples in Table 2 reveal that both markedness constraints and faithfulness constraints are ranked in a language-specific order. During the optimality-theoretic analysis, different markedness and faithfulness constraints usually do conflict, so the ranking of the constraints decides the right candidate as the output depending on the violation (of constraints) pattern.
The ranking of constraints can be demonstrated by a tableau in the OT analysis. In such a tableau, the candidates are arranged vertically while the constraints are ranked horizontally. In the following Tableau 1, it is shown how the optimal candidate is chosen by Evaluator uses the language’s constraint hierarchy to select the best candidate (s) through constraint interaction.
| Input | Constraint 1 | Constraint 2 |
|---|---|---|
| ☞ 1. Candidate 1 | * | |
| 2. Candidate 2 | *! |
From Tableau 1, we can see that Constraint 1 is ranked above Constraint 2. Constraint 1 is violated by Candidate 2. This is a fatal violation for this candidate, because of the high-ranking of Constraint 1. The fatal violation is marked by an exclamation (!) symbol. As a result, Candidate 1 becomes the optimal candidate, even though it violates the low-ranked Constraint 2. A hand symbol is used in OT to indicate the optimal candidate in a tableau.
To elaborate the OT, Silverman (1992) and Yip (1993) also proposed a perception-production approach to analyze Cantonese loanwords in terms of rules and OT. Silverman (1992) suggested a model consisting of two scansions or levels, i.e., Perceptual Level (Scansion One) and the Operative Level (Scansion Two). At the Perceptual Level, the foreign input is perceived as simply a string of acoustic signals constrained by the segment inventory of the native language. For example, since voicing is never contrastive in Cantonese, the English voiced stop in “game” is perceived as voiceless in [kɛm]. At the Operative Level (Scansion Two), the output of the Perceptual level is applied and adjusted to fit native syllable structures. The English word “stamp”, for instance, is perceived as [s tamp [H]] on the Perceptual Level, and adapted as [si [L] tam [H]] on the Operative Level by vowel epenthesis after /s/ to simplify the complex onset and by assignment if of low tone (L) for the epenthetic syllable. Yip (1993) adopts Silverman’s (1992) perspective to examine loanwords borrowed from English into Cantonese. She supports Silverman’s hypothesis that loanword phonology involves two levels, one is perceptual and the other one is phonological. However, at the Operative Level, she employs the OT perspective, which is different from the ruled-based analysis of Silverman to check the perceived input. The constraint-based analysis enables her to account for both loanword phonology and the phonology for the host language.
3. A Brief Sketch of Vietnamese and French Phonology with Reference to Loanwords Adaptation
Standard Vietnamese (Northern Vietnamese and typically Hanoi dialect) has a total of 19 initial consonants. There is one phoneme /p/, which is the counterpart of /ɓ/ only occurring in the initial position in some loanwords; e.g., pin /pin33/ ‘battery’ and pan /pan33/ ‘breakdown’. The inventory of Vietnamese initial consonants is given in Table 3 below.
| Labial | Labio-dental | Dental | Alveolar | Palatal | Velar | Glottal | |
|---|---|---|---|---|---|---|---|
| Plosive | ɓ(p) | t th | ɗ | c | k | ʔ | |
| Nasal | m | n | ɲ | ŋ | |||
| Fricative | f v | s z | x ɣ | h | |||
| Approximant | w | l |
Some researchers (e.g., Hoàng 1989, Nguyen 1997) do not include the glottal stop /ʔ/ in the initial inventory because it is not shown in the orthography of Vietnamese. However, other authors treat this glottal stop as a phoneme (e.g., Đoàn 1977, Thompson 1987, Pham 2009). Particularly, Pham (2009) argues that the glottal stop /ʔ/ is a phoneme and her analysis shows that the glottal stop patterns with its fricative counterpart /h/. In this study, we adopt the view of considering it as a phoneme so the glottal stop /ʔ/ is included in the initial consonant inventory of Vietnamese in Table 4 above.
| Consonants | p | t | c | k |
| m | n | ɲ | ŋ | |
| Glides | w | j |
Examples of /ʔ/ are given as follows.
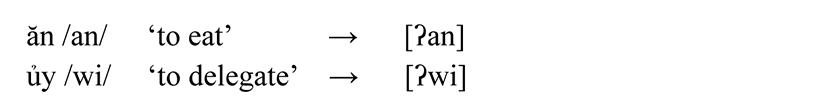
Vietnamese only allows voiceless stops /p, t, c, k/, nasals /m, n, ŋ/ and the glides /w, j/ in coda position (see Table 4 below). Certain final consonants are allophones of these sounds. The following gives the final consonant inventory of Vietnamese. The palatals and the plain and labialized dorsals are allophones of the same phoneme, i.e., [c], [k] and [k͡p] are allophones of [k] while [ɲ], [ŋ] and [ŋ͡m] are allophones of [ŋ].
After back-rounded vowels such as /u, o, ɔ/, the coda consonants /k, ŋ/ are produced as doubly articulated labial-velars /k͡p/ and /ŋ͡m/, as in /uk͡p45/ ‘Australia’, /ɔŋ͡m33/ ‘bee’ and /ok͡p45/ ‘screw’ or ‘snail’.
The majority of Vietnamese have only one syllable (except some borrowed words), which contain one vowel or a cluster of vowels with or without a consonant preceding or following. The number of phonemic vowels in Vietnamese is a matter of debate. In this study, we adopt the view that Vietnamese has eleven vowels, as illustrated in Table 5 below.
| Front | Central | Back | |
|---|---|---|---|
| High | i | ɯ | u |
| Mid | e | ɤ: ɤ | o |
| Low | ɛ | a: a | ɔ |
Table 5 shows the vowel inventory in Vietnamese. Only two vowels /a/ and / ɤ/ show a length contrast. Vietnamese vowels include the unrounded vowels /i, e, ɛ, ɯ, ɤ, ɤ:, a, a:/ and the rounded vowels /u, o, ɔ/.
There are three main diphthongs in Vietnamese which are /iə/, /ɯə/, and /uə/ that correspond to different forms in the orthography, as listed in Table 6.
The background information on phonology of French is based on Walker (2001), Féry (2003) and Kang et al. (2014). The variety of French discussed in our study is European French.
French has 21 consonants in its consonant inventory including approximants. The French consonant inventory is given in Table 7 below.
| Labial | Dental | Alveolar | Post-alveolar | Palatal | Labial-palatal | Velar | Uvular | |
|---|---|---|---|---|---|---|---|---|
| Plosive | p b | t d | k g | |||||
| Nasal | m | n | ɲ | ŋ | ||||
| Fricative | f v | s z | ʃ ʒ | ʁ1 | ||||
| Approximant | w | l | j | ɥ |
The consonantal phonemes inventory given in Table 8 reveals that French lacks the glottal fricative /h/ albeit having the orthographic letter ‘h’. This means that this letter is not pronounced in French.
| Front | Central | Back | |
|---|---|---|---|
| Oral vowels | i y | u | |
| e ø | ə | o | |
| ɛ œ | ɔ | ||
| a | (ɑ) | ||
| Nasal vowels | ɛ̃ (œ̃) | ɔ̃ | |
| ɑ̃ | |||
The inventory of vowels in French consists of two types (oral and nasal vowels) is presented in Table 8 below.
4. Phonological Changes at the Segmental Level
The segments being not part of the native Vietnamese inventory undergo changes. In this section, we will present an OT analysis of consonant segments. To account for the phonological changes at the segmental level, we use the following constraints for our analysis, the IDENT-F constraint for constraints of Place, Voice and Manner.
OK-σ: A package constraint that has been mentioned in the previous section.
IDENT-PLACE: Segments have the same place features in both input and output.
IDENT-MANNER: Segments have the same manner features in both input and output.
IDENT-VOICE: Segments have the same voice features in both input and output.
The forms that are closest to the offending segments are used to substitute the consonant segments which are illicit in the native language. From the corpus of loanwords, we note that the changes of consonant segments can be categorized into onset and coda segments due to the restriction on codas in native Vietnamese.
In this section, we examine the adaptation that foreign segments undergo in the Vietnamese language, which will be explained by the OT tableaux. First of all, we observe that the French voiced stop /g/ is replaced by the Vietnamese fricative phoneme /ɣ/ in onset, as in /ɡɑto/ > [ɣato] ‘cake’ or in /gamɛl/ > /ɣamɛn/ ‘tin can’. We can explain this phonological change in terms of OT.
Let us take the French word /ɡɑto/ which changes to [ɣato]. We can see that /g/ is changed to /ɣ/. In native Vietnamese, /g/ is not present, so it substitutes this segment with the closest form. Here we can see that the place of articulation remains the same (velar) but the manner of articulation changes. In this case, the stop becomes a fricative. To account for this phonological change, besides the Ident constraints of Voice, Place and Manner, we require the highest ranked constraint OK-σ. In other words, the native language is very strict on foreign segments so it does not allow any segments which are illicit. However, the ordering of the three constraints IDENT-VOICE >> IDENT-PLACE >> IDENT-MANNER tells us the minimal repair strategy employed. A change of manner feature is preferred to one of voice or place. Tableau 2 below illustrates the adaptation of /ɡɑto/ > [ɣato] with an OT tableau.
| /ɡɑto/ | OK-σ | IDENT-VOICE | IDENT-PLACE | IDENT-MANNER |
|---|---|---|---|---|
| a. /ɡɑto/ | *! | |||
| b. ☞/ɣato/ | * | |||
| c. /ka.to/ | *! | |||
| d. /ta.to/ | *! |
As can be seen in Tableau 2, candidate (a) violates a very high ranked constraint, OK-σ as it has the segment /g/, which is not allowed in the native language. Candidate (c) also violates another high ranked constraint IDENT-VOICE, prohibiting a voice change. Candidate (d) violates another high ranked constraint called IDENT-PLACE. So candidate (b) becomes the optimal one with a violation of a lower ranked constraint, IDENT-MANNER.
Next, we examine the obstruents /ʃ/ and /ʒ/ which change to /s/ and /z/. Examples of this phonological change are given as follows.

It can be seen that native Vietnamese do not have the obstruent segments /ʃ/, /ʒ/ so it substitutes them with the closest sound forms /s/ and /z/. In this case, we can see that the manner of articulation remains the same (fricative), and place of articulation changes from palato-alveolar to alveolar.
We take the example of /ʒakɛt/ > [zakɛt] to explain for this change.
As can be seen in Tableau 3, candidate (a) violates a very high ranked constraint, OK-σ. Hence, it is not allowed in the native language. Candidate (b) violates two high ranked constraints, IDENT-VOICE and IDENT-PLACE. Therefore, candidate (c), which violates only the lower ranked constraint IDENT-PLACE, becomes the optimal candidate.
| /ʒakɛt/ | OK-σ | IDENT- VOICE | IDENT-PLACE | IDENT-MANNER |
|---|---|---|---|---|
| a. /ʒakɛt/ | *! | |||
| b. /sakɛt/ | *! | * | ||
| c. ☞/zakɛt/ | * |
Another adaptation of obstruents is for the uvular fricative /ʁ/, which is realized as /z/ in onset position. Examples of this adaptation are presented as follows.

For example, the French word /kaʁɔt/ becomes /kazot/ which can be seen in Tableau 4. It can be noted that /ʁ/ has been changed into /z/. It can be explained that the French sound /ʁ/ which is not present in native Vietnamese was substituted with the closest form /z/. It is evident that manner of articulation remains the same (fricative) and the place of articulation changes from uvular to alveolar.
| /kaʁɔt/ | OK-σ | IDENT- VOICE | IDENT-PLACE | IDENT-MANNER |
|---|---|---|---|---|
| a. /ka.ʁɔt/ | *! | |||
| b. /ka.sɔt/ | *! | * | ||
| c. ☞/ka.zɔt/ | * | |||
| d. /ka.kɔt/ | *! | * | ||
| e. /ka.gɔt/2 | * |
To account for this phonological change, we also need the same constraints OK-σ, IDENT-VOICE, IDENT-PLACE and IDENT-MANNER as seen in Tableau 4 below.
Here, we can see that OK-σ, the highest ranked constraint bans candidate (a) since the French input fricative /ʁ/ is disallowed in Vietnamese. Candidate (b) is not allowed because it also violates another high ranked constraint, IDENT-VOICE. Candidate (d) is ruled out it also violates the high ranked constraint, IDENT-VOICE. Therefore, candidate (c) wins and becomes the optimal one.
The consonant segmental changes in coda position can be summarized as below:
-
The fricatives /f, s, ʃ, ʒ, ʁ/ become continuants /p, t, k/ sounds.
-
The lateral approximant /l/ becomes nasal /n/.
-
The voiced stops /b, d, g/ change to voiceless stops /p, t, k/.
Examples of the adaptation of /f, s, ʃ, ʒ, ʁ/ are given as follows.

In order to account for these phonological changes, we propose an optimality-theoretic analysis. It is observed that in the Vietnamese phonemic inventory fricative sounds are not allowed in coda. Hence, the borrowed words from French, with these sounds, are always substituted by their closest counterparts with similar place of articulation.
Consider the French word /kaskɛt/ > [katkɛt], where /s/ is realized as /t/ in coda position presented in Tableau 5 below.
| /kaskɛt/ | OK-σ | IDENT- VOICE | IDENT-PLACE | IDENT-MANNER |
|---|---|---|---|---|
| a. /kaskɛt/ | *! | |||
| ☞b. /katkɛt/ | * | |||
| c. /kapkɛt/ | *! | * |
As can be seen in Tableau 5, candidate (a) violates a very high ranked constraint, OK-σ as it is not allowed in the host language. Candidate (c) violates another high ranked constraint, IDENT-PLACE and IDENT-MANNER. Candidate (b), although violating a low constraint, IDENT-MANNER, becomes the optimal one.
The word /kɔʁsɛ/ becomes /kɔkse/, for instance. It is noted that the segment /ʁ/ is substituted by /k/ in word-medial position. In this case, the word-medial position is mentioned as the segment /ʁ/ is deleted in word-final position (Tableau 6 below). To account for this phonological change, no new constraint is required.
| / kɔʁsɛ / | OK-σ | IDENT- VOICE | IDENT-PLACE | IDENT-MANNER |
|---|---|---|---|---|
| a. /kɔʁsɛ / | *! | |||
| b.☞/kɔksɛ/ | * | * | ||
| c. /kɔpsɛ/ | * | *! | * | |
| d. /kɔtsɛ/ | * | *! | * |
As shown in Tableau 6, the first candidate /kɔʁsɛ/ violates the most marked evaluator, OK-σ as it has the coda /ʁ/ which is not allowed in the native language. The third candidate /kɔpsɛ/ violates another high ranked constraint. Therefore, the second candidate becomes the optimal one as it violates the lower ranked constraint, IDENT-MANNER.
Next, we observe that the lateral approximant /l/ becomes the nasal /n/ in coda position. The segment /l/ is allowed in onset but it is banned in coda position in native Vietnamese. When French words containing the segment /l/ in the coda are borrowed into native Vietnamese, it is integrated to the closest sound; that is /n/. Examples of adaptation of coda /l/ are given as follows.

Let us consider the example of the word /mɔdɛl/ > [mɔdɛn] in which /l/ is replaced by /n/. We also use the same constraints as above to explain for this change and the tableau is shown in Tableau 7 below.
| mɔdɛl | OK-σ | IDENT-VOICE | IDENT-PLACE | IDENT-MANNER |
|---|---|---|---|---|
| a. /mɔdɛl/ | *! | |||
| b. /mɔdɛm/ | *! | * | ||
| c. ☞/mɔdɛn/ | * | |||
| d. /mɔdɛr/ | *! |
Obviously, the optimal candidate is (c) because it violates the lowest constraint, IDENT-MANNER. The other candidates (a), (b) and (d) violate the higher constraints which are OK-σ (i.e., coda violation) and IDENT-PLACE.
Observing the voiced stops /b, d, g/ from source language, we found that they are realized as voiceless stops /p, t, k/ in coda position. Examples of this adaptation can be seen as follows.

Since Vietnamese only allows voiceless stops in coda position, all voiced stops such as /b/, /d/, /g/ from the donor language are substituted by their voiceless counterparts. To account for this phonological change, we also need the constraints OK-σ, IDENT-VOICE, IDENT-PLACE and IDENT-MANNER.
However, for the segments to become voiceless stops and not change to other sounds, we need another constraint IDENT [±SON], which should be higher-ranked than the other three constraints of voice, place and manner identity.
The introduction of this constraint, IDENT [±SON], makes the correct prediction for the data given earlier, too. In all the forms given earlier, the feature [±SON] is preserved.
Let us take the example of the foreign word /asid/ which becomes [asit] in which coda /d/ is adapted as /t/. The phonological change is analyzed in the tableau of constraints which is shown in Tableau 8 below.
| /asid/ | OK-σ | IDENT [±SON] | IDENT-VOICE | IDENT-PLACE | IDENT-MANNER |
|---|---|---|---|---|---|
| a. /asid/ | *! | ||||
| b. ☞/asit/ | * | ||||
| c. /asip/ | * | *! | |||
| d. /asin/ | *! | * |
The very high ranked constraint OK-σ (i.e., CODA License) bans candidate (a). Candidate (d) also violates another high ranked constraint, IDENT [±SON]. Both candidates (b) and (c) violate the same constraint IDENT-VOICE, but candidate (c) has more violations. Therefore, candidate (b) becomes the optimal one.
We observe that some illicit segments in word-final position are deleted. However, in word-medial position; they are substituted by the most similar Vietnamese sounds. For instance, the segments /ʁ/ and /ʒ/ in word medial position are replaced by /k/and /t/ respectively as mentioned earlier. Most deleted segments are obstruents, which are illicit in Vietnamese. Examples of consonant deletion are given as follows.

Let us consider the word /ekɛʁ/, which changes to /ekɛ/. We can see that the coda /ʁ/ in word-final position is deleted instead of being substituted by /k/, as in word-medial position. The constraints to account for this phonological change are OK-σ, MAX-SON, IDENT-F, DEP-IO, ALIGN-R and MAX-IO and are presented in Tableau 9 below.
The results in Tableau 9 indicate that here the highest ranked constraint OK-σ bans candidates (a) and (b) from becoming the optimal candidate since they have the coda and onset /ʁ/, which is not permissible in the native language. Another high ranked constraint IDENT-F disallows the candidate (c) (as it has a violation of Ident-place and manner). Therefore, candidate (d) wins and becomes the optimal candidate.
| /ekɛʁ/ | OK-σ | MAX-SON | IDENT-F | DEP-IO | ALIGN-R | MAX-IO |
|---|---|---|---|---|---|---|
| a. /ekɛʁ/ | *! | |||||
| b. /ekɛʁe/ | *! | * | * | |||
| c. /ekɛk/ | *!* | |||||
| d. ☞/ekɛ/ | * | * |
In the case of adaptation of French vowels, the loanwords strictly conform to the Vietnamese vowel inventory. The illicit vowels are replaced by the closest forms, or in some cases, the illicit segments also undergo some changes. This is indicative of the fact that the markedness constraints of Vietnamese are very high-ranked. To explain the phonological changes, we require the constraint OK-V, acting as a package of different constraints. The OK-V constraint consists of three constraints. First, vowels must be oral. This means that nasal vowels are not allowed. Second, no front rounded vowels are allowed. The third constraint bans the vowel schwa /ə/ in loanword phonology. The OK-V can be summarized for ease of reference:
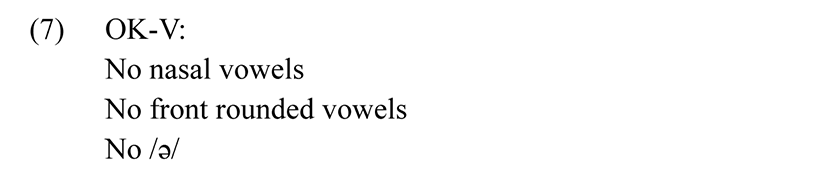
The OK-V constraint implies that Vietnamese has to introduce some repair mechanisms to accommodate French vowel segments that violate any of these constraints. Nasal vowels will be nativized and certain vowels segments disallowed in Vietnamese will have to be changed. In fact, the OK-V is also a part of the package OK-σ constraint as Vietnamese loanword phonology restricts all illicit segments.
Some faithfulness constraints required to penalize the changes to the input are presented below:

When we examine the adaptation of vowels into Vietnamese from French, we note that the height feature is retained in the loanwords. This indicates us that IDENT-[±HIGH] is a high ranked constraint.
The rounded high /y/ is adapted as /wi/, /u/ or /i/, as can be seen below. It seems that /wi/ is more frequently adapted as the features of the segment /y/, i.e., [+round] and [+high] can be both retained.

The examples indicate that the French input /y/ is mainly realized as /wi/. However, /y/ is pronounced as /u/ in [vizut] and /i/ in [leɣim] which are the exceptions and this pronunciation reveals the influence of orthography of French loans in Vietnamese. Now let us discuss the word /bys/, which changes to /bwit/. To account for this phonological change, we require the constraints OK-V, IDENT-[±HIGH], IDENT-[±BACK], IDENT-[±ROUND], DEP-IO and MAX-IO see Tableau 10 below.
| /bys/ | OK-σ | IDENT-[± HIGH] | IDENT-[±BACK] | IDENT-[±ROUND] | DEP-IO | MAX-IO |
|---|---|---|---|---|---|---|
| a. /bys / | *! | |||||
| b. /but3/ | *! | |||||
| c. /bit/ | *! | |||||
| d. ☞/bwit/ | * |
Candidate (a) is banned because it violates the highest ranked constraint, OK-σ, which does not allow the front rounded vowel /y/. The data in Tableau 10 show that Candidates (b) violates IDENT-[±BACK], in which /y/ > /u/ the feature [back] is violated. Candidate (c) violates another high- ranked constraint IDENT-[±ROUND], in which /y/ > /i/ the feature [round] is violated. Thus, both candidate (b) and (c) are ruled out. Candidate (d) violates a lower ranked constraint, DEP-IO with an epenthesis of the glide /w/ and becomes optimal. This adaptation explains the preservation of [round] and [high] features of the input /y/. The insertion of the glide /w/ is the frequent adaptation of the French input /y/ to preserve all the features of the input. The change of /y/ to /u/ in /viʁys/ > [vizut] ‘virus’ and /y/ to /i/ in /leɡym/ > [leɣim] ‘vegetable’ are determined by Vietnamese orthography.
The high front rounded /ø/ becomes a high, back, unrounded /ɤ/. The word /nø/ changes to [nɤ] to illustrate the adaptation of the illicit segment /ø/ from the donor language.
Tableau 11 shows that the dominance of IDENT-[±HIGH] over IDENT-[±BACK] and IDENT-[±ROUND] makes the changes of the round feature tolerable, hence candidate (c) is a possible output. The mid front rounded /œ/ becomes a close-mid unrounded /ɤ/ or a diphthong /ɯə/. Examples of the adaptation of /œ/ > /ɤ/, /ɯə/ can be seen below. The substitution of /œ/ to /ɯə/ is an exception.
| /nø/ | OK-σ | IDENT-[±HIGH] | IDENT-[±BACK] | IDENT-[±ROUND] | DEP-IO | MAX-IO |
|---|---|---|---|---|---|---|
| a. /nø/ | *! | |||||
| b. /nɔ/ | *! | * | ||||
| c.☞/nɤ/ | * | * | ||||
| d. /ne/ | *! | * |

Noticeably, the French oral vowel /œ/ is adapted as /ɤ/ which is presented in Tableau 12. Here, we can observe that the mid-feature remains the same and the round feature changes. For these phonological changes, we require the same constraints as used earlier. Candidate (a) is ruled out by the highed-rank constraint, OK-V since it has the illicit vowel, which is disallowed in Vietnamese. Candidate (b) violates two other high-ranked constraints, IDENT-[±HIGH] and IDENT-[±BACK]. Candidates (c) and (d) violate IDENT-[±ROUND]. Candidate (c) violate IDENT-[±BACK] and IDENT-[±ROUND] and yet it is the optimal one.
| kœʁ | OK-σ | IDENT-[±HIGH] | IDENT-[±BACK] | IDENT-[±ROUND] | DEP-IO | MAX-IO |
|---|---|---|---|---|---|---|
| a. /kœʁ/ | *! | |||||
| b. /ko/ | *! | * | ||||
| c. ☞/kɤ/ | * | * | ||||
| d. /ke/4 | * |
Examples of adaptation of nasal vowels are presented below. The corpus data show us that there is a correlation between the nasal vowels and the adjacent consonantal segments.

In native Vietnamese, only oral vowels are allowed. It does not have nasal vowels as in French, so the illicit vowel segments are replaced by an oral vowel and its nasal feature is preserved by an additional nasal consonant that follows. From the data given above, it is clear that /ŋ/ is a default nasal that is inserted when the nasal vowel becomes an oral vowel (see (a), (c) and (d) as mentioned). /ŋp/ or /ŋb/ is realized as /m/ when it occurs in the word final position. Rather than describing this change as two separate processes of assimilation and deletion, this phenomenon could be termed ‘nasal coalescence’ in which two input segments, the nasal and the following labial obstruent are fused into one output segment, which retains the manner feature of the nasal and the place feature of the labial obstruent. Nasal coalescence /ŋ + p/ →[m] can be illustrated in the following figure.
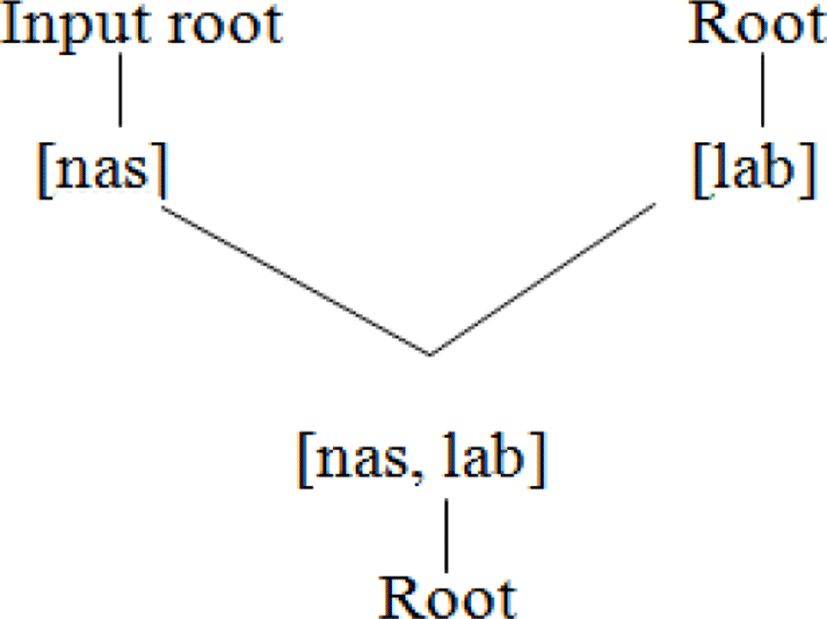
Coalescence is a strategy used only when the /ŋp/ cluster occurs in the word final position. It does not coalesce in the word medial position e.g., /kɔ̃pa/ > [kɔmpa] and not *[kɔma]. The nasal coalescence that we note in the word final position poses a problem as an underlying segment /b/, which gets elided, determines the form of the nasal that appears on the surface. This phenomenon bears a strong resemblance to derivational opacity. In OT theory, coalescence is seen as a violation of the constraint UNIFORMITY, proposed by McCarthy & Prince (1994). To make it clearer, two additional constraints are discussed as follows.

Tableau 13 below shows the tableaux for the derivation of loanwords /kɔ̃pa/ > [kɔmpa] ‘compas’ and /bɔ̃b/ > [bɔm] ‘bomb’.
| /kɔ̃pa/ | OK-σ | IDENT-[±NASAL] | AGREE (LABIAL) | UNIFOR-MITY | DEP-IO | ALIGN-R | MAX-IO |
|---|---|---|---|---|---|---|---|
| a. /kɔ̃pa/ | *! | ||||||
| b. /kɔpa/ | *! | ||||||
| c. /kɔŋpa/ | *! | * | |||||
| d. ☞/kɔmpa/ | * | ||||||
| e. /kɔma/ | * | * |
As can be seen in Tableau 13, candidate (a) is ruled out due to its highest ranked constraint, OK-σ. Candidate (b) violates the constraint IDENT-[±NASAL], a high-ranked constraint due to the deletion of the nasal feature. Candidate (c) is ruled out by a high-ranked constraint, AGREE (LABIAL). Candidate (e) violates the constraints UNIFORMITY and MAX-IO. Candidate (d) becomes the optimal one as it violates only the low ranked constraint DEP-IO.
The adaptation of the word /bɔ̃b/ > [bɔm] is illustrated by the following Tableau 14 below.
| bɔ̃b | OK-σ | IDENT-[±NASAL] | AGREE (LABIAL) | UNIFOR-MITY | DEP-IO | ALIGN-R | MAX-IO |
|---|---|---|---|---|---|---|---|
| a. /bɔ̃b/ | *! | ||||||
| b. /bɔb/ | *! | * | * | ||||
| c. /bɔmb/ | *! | * | |||||
| d. /bɔp/ | *! | ||||||
| e. /bɔŋb/ | *! | * | |||||
| f. /bɔm/5 | * | * | * | ||||
| g. /bɔn/ | *! | * | * | ||||
| h. /bɔŋ/ | *! | * | * |
Tableau 14 indicate that candidates (a), (b), (c) and (e) violate the highest ranked constraint OK-σ (i.e., Coda license). Candidates (g) and (h) are ruled out by a high ranked constraint AGREE (LABIAL). Thus, candidate (f) becomes the optimal as it violates low ranked constraints DEP-IO and ALIGN-R.
5. Conclusion
As can be seen, examination of the permissible Vietnamese substitutes for foreign consonants and vowels showed that the recipient language speakers adapt the foreign language input at two levels, i.e., perception and production proposed by Silverman (1992) and Yip (1993). The sounds that are first perceived by the Vietnamese speakers are then produced according to the production grammar constraints. The constraint-based approach proposed in this paper explains various adaptation patterns noted in Vietnamese. Firstly, the blanket constraint OK-σ says that French words are perceived according to the phonological system of the native language. The markedness constraint of Vietnamese is high ranked. Secondly, it is noted that sonorants survive in most contexts than obstruents and this was explained by the use of the constraint MAX-SON. However, when there are two sonorants in the coda of a syllable, the second one survives. This was explained by the use of the constraint ALIGN-R. Similarly, when looking at simplex sounds, we noted that contrasts in place and voice are perceptually more distinctive than contrasts in manner features, and the constraint ranking of IDENT-VOICE >> IDENT-PLACE >> IDENT-MANNER triggers the mapping of the consonants from French to Vietnamese. The analysis of vowel phoneme substitution reveals the following ranking.
The mapping of nasal vowels from French to Vietnamese showed that the nasal feature survives by nasal insertion and the nasal consonant added is the default nasal /ŋ/. However, there is a labial assimilation of the epenthesied nasal consonant. This was explained by the use of AGREE (LABIAL).
Since loanword adaptation is in the state of flux, we find certain constraints that are floating, which leads to variations in pronunciation. The floating of the two constraints: ALIGN-L and DEP-IO allows the variations in the pronunciation of some words where we can have either epenthesis or deletion to break up the clusters which are not allowed in the native language.
6. Implications
This article has some practical implications for Vietnamese phonology and loanword phonology in general. Firstly, the findings of the study reveal that the constraints needed and their rankings play an important role in loanword adaptation in Vietnamese. For example, the contrasts in voicing are perceptually more distinctive than contrasts in place and in manner. This perceptibility of consonantal features leads to the ranking of IDENT (VOICE) >> IDENT (PLACE) >> IDENT (MANNER), which determines the mapping of segments from French to Vietnamese. This ranking seems to violate the universal ranking of featured identity constraints, i.e., IDENT (MANNER) dominates IDENT (PLACE) and IDENT (VOICING/ ASPIRATION).
Secondly, the study proposes a more analytical perspective on Vietnamese loanword phonology by giving phonological explanations, in contrast to previous research on loan adaptation in Vietnamese (e.g., Barker 1969, Nguyen 2007), which mainly gave descriptions in relation to general phonology, etymology or sociolinguistics.
Thirdly, this research also supports the perception-production approach (Silverman 1992, Yip 1993) which proposes that the borrower speakers adopt a loanword at two levels, i.e., Perceptual and Production level. At the Perceptual level, Vietnamese speakers perceive the input segments which are similar or close to their native language and produce them according to their production grammar. In the Vietnamese data that we examine, we note that certain segments are more salient than others and are thus preserved. These are faithfully copied from the donor language and even when alterations are required (due to higher ranked constraints), the changes are minimal. So, perception governs production. Loanword adaptation is governed by phonetic cues and phonological factors.