




1. Introduction
HKE1 has been studied under different topics in recent years. While many of the previous studies focused on the features of HKE (e.g., Hung 2000, Setter 2006, Setter et al. 2010, Sewell & Chan 2010, Sung 2015, Hansen Edwards 2016a, 2019, and Wong 2017, etc.), a number of researches have also emerged to investigate HKE in different contexts, especially concerning the intelligibility of HKE (e.g., Sewell 2012, Zhang 2014, Hansen Edwards et al. 2018). However, even though earlier studies have shown the features of HKE to be unique and highly intelligible to listeners worldwide, there has been a lack of emphasis on how the consonant features of HKE to be included in the language contact are processed. The traditional contrastive analysis in language contact normally regards features of new Englishes as “errors”. Nonetheless, with the influence from the field of study of world Englishes, facets of different Englishes are expected to be appreciated as “features” rather than “errors” because of the poly-centric nature of new Englishes. The current paper therefore aims to analyze the consonantal features of HKE from a mini-corpus, which consists of 29 speakers from Hong Kong, who are of a wide range of ages and occupations. Moreover, the current study aims to outline a new categorization of HKE speakers which shows how HKE speakers could be linearly distributed along a new categorization called the HKEC, unlike the earlier kind of categorizations (e.g., Zhang 2014, Lam 2017), which used a stereotyping concept. In the following, the designs of the current paper will be outlined followed by a detailed analysis of the five consonantal features of HKE. A world Englishes version of contrastive analysis between HKE and Cantonese will also be included in the discussion.
2. Literature Review
As mentioned above, studies on HKE are diverse, ranging from phonetics and syntax to education and pedagogy (Chan 2016). In this part, a brief literature review on relevant studies will be introduced followed by the aims of the current study. Since the present research focuses only on segmental features of HKE, the emphasis will be placed on relevant literature.
Language contacts have been yielding new forms of varieties of languages (Kim 2001), HKE is also the result of language contacts between Cantonese (L1) and English (L2) in Hong Kong due to the colonial background of this Southeast Asian city. English is widely spoken as a second language, as it is a compulsory subject to school children from the age of three. The MOI of some secondary schools and all universities in the city is also English. However, English is regarded as a language for work and education while Cantonese is used in most daily conversations for intimacy, especially for language at home. The diversity of usage between the two languages in Hong Kong has been regarded as a form of bilingualism since the last decade (Zhang 2014). Recently, a sign of trilingualism was also discovered because of the closer contact with mainland China after the handover in 1997 (Chan 2018, 2019). This language contact yields the phonetics of HKE, which has been broadly investigated by scholars in the last two decades.
Hung (2000) investigated the phonetic inventories of HKE using a sample of 15 university students; he concluded that HKE has smaller vowel and consonant inventories compared with British English, mainly due to a merging of vowels and the lack of voiced consonants. Various research has been done to examine the HKE inventory, some of which specifically studied several features, including TH-fronting (Hansen Edwards 2018); CCM (Setter 2008); L vocalization (Wong & Setter 2002); /n/-/l/ conflation (or merger) (Sewell & Chan 2010); and voicing contrasts (Setter et al. 2010), etc. While most of the above studies tried to provide a full picture of the inventory of HKE, most of them only included a small and/or narrow population as samples, including the more detailed studies like Deterding et al. (2008), Kirkpatrick et al. (2008) and Setter et al. (2010). As Bolton et al. (2020) described, “Most of the informants for such studies [of HKE] have been college and university students, whose command of the language might be regarded as ‘mid-proficiency’ or ‘mid-range’” (p. 468). In fact, the speakers in those previous studies of HKE were usually university students (e.g., Hung 2000, Deterding et al. 2008, Setter et al. 2010, Hansen Edwards 2018), which is only representative to the younger generation of HKE speakers. The number of informants in those studies was generally small, ranging from five (Setter et al. 2010) to 15 in Hung (2000) and Deterding et al. (2008). Due to the small number of informants and narrow spectrum of speakers, those studies may only reflect just a part (mostly young Hongkongers who studied in university) of the spectrum in HKE. Chan (2020a) suggested that there is a HKEC, which indicates that the HKE speakers in Hong Kong have a different number of HKE features and these speakers can be put on a continuum according to the number of those features. The missing puzzles of both the older HKE-speaking generation and occupation other than university students were partly found by Sewell & Chan’s (2010) study, in which video clips of 25 speakers of HKE from local TV programs were analyzed. Sewell & Chan (2010) analyzed their database of the 25 speakers with seven different consonantal features, including TH-stopping, TH-fronting, L vocalization, /l/-/n/ conflation, /r/ substitution, /v/ substitution, and initial CCM. Their findings showed that L-vocalization and TH-stopping are the more prominent features in HKE. However, even though Sewell & Chan (2010) attempted to fill the void of previous literature, the 25 speakers in their study were imbalanced in gender (only four males were involved) and the number of informants was limited as well.
The present study follows Sewell & Chan’s (2010) approach of using video clips with several modifications to overcome some of the problems mentioned above. The present study analyzes a “mini-corpus” of HKE speakers from online video clips from a wider and more balanced range of informants (more details will be discussed in the next part). Moreover, the present paper employs a contrastive analysis approach under the world Englishes paradigm to account for the HKE features, which has rarely been found in the existing literature. The classic CAH was proposed by Fries (1945). However, the classic CAH identifies the differences between L1 and L2 as “errors” (Yang 1992), which is different from “features”, which is the more neutral term preferred by world Englishes scholars (Chan 2020b). Since the study of the world Englishes paradigm is about the “pluralism and inclusivity” of the different Englishes worldwide that continue to spread (Bolton 2005: 78), the features of each English variety around the world are seen as unique features that are valued for their cultural understanding with each other. Therefore, the modified CAH used in this paper, instead of outlining the “errors” as the goal of analysis, tries to ascertain the frequency of the target features among the sample size, which then deduces the commonness of the features among Hongkongers along the HKEC. Hence, making use of the more all-rounded corpus in the present study in order to find out the consonantal features of HKE and the commonness of the features along the HKEC, three research questions are raised in this paper:
3. Methodology
In the current investigation of segmental features of HKE, various sound clips were collected from the Internet and analyzed by the two researchers who specialized in phonetics and phonology. With reference to similar research from Sewell & Chan (2010), the reasons for using sound samples from the Internet instead of collecting data face-to-face is multifaceted. First, the online data provides an opportunity to collect samples from a wider range of speakers, in both age and occupation. This is because for most of the previous studies in HKE, the participants that were recruited were around 20 years old (e.g., Deterding et al. 2008, Hung 2000, etc.), probably due to the fact that they collected data from university students. The use of online samples provided a huge chance for an unlimited resource of speakers from all walks of life for researchers in this respect. Second, the online data provides more natural speech. Unlike the traditional data collection, which requires speakers to read out scripts and word lists (e.g., Hung 2000, Hansen Edwards et al. 2018), online data provides more authentic speech in which speakers speak freely on various topics. It is also different from experiments that used semi-structured interview data, for which the speakers might be stressed during a one-to-one interview in an enclosed, unfamiliar situation. Speakers from the online data are arguably more relaxed when they talk, probably because they are doing something they are familiar with and that they are obligated to do. Lastly, it is also because of the current COVID-19 situation, in which face-to-face contacts are discouraged. Thus, the current data collection method may also be seen as an opportunity to try out different data collection processes using Sewell & Chan’s (2010) methods, especially under this pandemic situation.
Since the online data was collected in less-controlled environments, the researchers employed several rules to ensure the authenticity of the video clips. First, the speakers in the clip must be identifiable, which provided us a chance to know the background of the speakers, including their education backgrounds. Second, the sounds in the videos must be clear enough for analysis. The quality of the sound files extracted from the videos is set at 16-bit stereo (44.1 kHz) in WAV format to ensure quality sound. Third, the speakers in those online videos should be speaking un-scripted to prevent unauthentic, controlled speech. In order to prevent scripted situations, most of the videos were Q&A sections in press conferences, where speakers faced questions from various reporters. Questions from reporters working in renowned English presses like Reuters are mostly preferred for the researchers, while local presses that have closer connections to the government were not preferred for various reasons.
Based on the criteria above, 29 speakers (14 females, 15 males) from 37 different online video clips (2,774 seconds of data in total, ranging from 12 seconds to 272 seconds) were collected and formed the mini corpus of 5,791 words in the current study. The videos were considerably recent recordings of press conferences during July 2019 to July 2020. All 29 speakers were assumed to be using Cantonese as their L1s, based on their accents. According to the backgrounds of the speakers, which were open to the public, the 29 speakers’ ages were from the mid-30s to mid-70s, with all of them having a minimum education level of bachelor’s degree, nine of them having a master’s degree, and three of them having a doctorate (details of the speakers are attached in the Appendix).
In Sewell & Chan (2010), the disadvantages of using “Media English” were outlined in detail, which includes (i) the low representativeness with respect to the whole population; (ii) an imbalance in gender, occupation, and age; (iii) unnatural speech from the studio’s interviews; and (iv) the scripted nature of some media scenes. The first point (i) has been an on-going debate for most of the linguistic research; for example, Biber (1993) suggested that representativeness of a research is defined by the variability of the given population that is covered and McEnery et al. (2006), who suggested that for the sampling of population in a linguistic study that involves a corpus, “presently there is no objective way to balance a corpus or to measure its representativeness” (p. 21). Even though the current study is not a corpus study, the mini database that is used is considerably large compared to previous studies (e.g., Hung 2000, Deterding et al. 2008, Setter et al. 2010, Sewell & Chan 2010, etc.), which could be said as covering a wider range of speakers. This also reflects on the second point (ii). In the current study, various factors are balanced, which includes gender ratio (14M:15F); occupation (from firefighters and police to senior government officers); and age range (mid-30s to mid-70s). The sampling of the current study covers a wider scope of participants than previous studies, which normally only involves university students (e.g., Hung 2000, Deterding et al. 2008, Kirkpatrick et al. 2008, Hansen Edwards 2016b, etc.). For (iii) and (iv), as mentioned above, the current study collected samples from the Q&A sessions of press conferences in Hong Kong. According to Gregory (1967), spontaneous speech is different from non-spontaneous speech in various linguistic features. Maekawa et al. (2000) also stated that spontaneous speech may contain more variables, which is desirable for understanding the language. The current study only uses data from Q&A sections of press conferences, of which the questions were raised by non-local renounced media companies to ensure that the answers from the speakers were likely to be unscripted and more importantly, not pre-cued.
The data was then analyzed by the two researchers following several steps. First, the sounds were transcribed verbatim and phonetically separated by the researchers, then subsequently compared with an average inter-rater error of 91.5%. Second, all the target sounds were isolated and were analyzed phonetically according to the features that were selected. When there was a disagreement between researchers, the respective sound was isolated for discussion. At the end, 1,453 words were taken out for the five target features for further analysis.
4. Findings
In this present study, five consonantal features that are commonly found in HKE are examined. As mentioned in the previous section, word tokens with HKE consonantal features were selected and grouped according to their features. There are, in total, five groups: (i) TH stopping/fronting; (ii) L vocalization; (iii) [n, l]/[s, ʃ] conflation; (iv) /r/, /v/, /w/ substitution; and (v) CCM. Table 1 provides brief definitions, related literature, and examples from our data of the five consonantal features. It must be noted that the brief definitions provided in Table 1 are not presuppositions of how they “should” be pronounced, but instead, it is more of a description of how they differ from “standard” varieties such as RP (Sewell & Chan 2010).
| Consonantal Feature | Brief Definition | Related Literature | Examples from Data |
|---|---|---|---|
| TH Stopping/Fronting | Substitution of voiced and voiceless dental fricative /ð/ and /θ/ with [d] and [f] respectively | Deterding et al. (2008), Hansen Edwards (2018) | Frequently in the onset position, e.g., the, their; sometimes in coda position, e.g., with, growth. Abundant data on functional words, e.g., the, that. |
| L Vocalization | 1. Using a full vowel [o] or [u] to replace coda /l/ 2. Deletion of coda /l/ |
Deterding et al. (2008), Setter et al. (2010) | Frequently in words ending with /əl/, e.g., normal |
| [n, l]/[s, ʃ] Conflation | /n/ and /l/, /s/ and /ʃ/ are in free variation in onset position. | Hung (2000) | /n-l/ conflation is more frequent than /s, ʃ/ e.g., line /laɪn/ → [naɪn] |
| /r/, /v/, /w/ Substitution | /r/ /w/ and /v/ are pronounced interchangeably in any word position. | Hung (2000), Sewell & Chan (2010) | Tendency leans towards a substitution from /v/ towards [w] and /r/ towards [w], e.g., invite /ɪnˈvaɪt/ → [inwite] |
| CCM | Modification of consonant clusters with either deletion or substitution | Chan & Li (2000), Sewell & Chan (2010) | Frequently in onset position and coda position (with/without suffixes), e.g., most /məʊst/ → [məʊs], contacts /ˈkɒn.tæktz/ → [ˈkɒn.tæt] |
Doubtlessly, there are other consonantal features in HKE, such as devoicing of voiced consonants, substitution of /v/ with /f/, etc. However, the current study decided to solely focus on the five features based on the following reasons. First, the five consonantal features selected are relatively common in HKE, as stated in various previous literature. This shows that the selected features are representative and worth investigating. Second, previous studies of HKE are taken into consideration in the selection of features. Sewell & Chan (2010) investigated seven HKE consonantal features, including TH stopping, TH fronting, L vocalization, [n, l] conflation, /r/ substitution, /v/ substitution, and initial CCM. Similar features were found in the data, but another way of grouping the features was used with the aim of covering more features and providing a more extensive view on them. For instance, TH stopping and TH fronting are grouped together, as they are both features related to the TH sound. The same applies to initial and final CCM, and also /r/ and /v/ substitution. Also, unlike in Sewell & Chan (2010), where [s, ʃ] conflation was not found, both [n, l] and [s, ʃ] conflation occurs in our data. Therefore, both types of conflation were considered and grouped together for convenience of analysis.
To provide a more accurate analysis of the consonantal features, percentage agreement between raters for each feature was calculated using the same method as Hansen Edwards (2017). This intra-rater percentage agreement was calculated to show if the two listeners agree on the occurrence of a feature in the same word token so as to establish whether or not the speakers used the features. As can be seen in Table 2, the two researchers reached a high level of agreement on the presence of each feature. In general, the rates of agreement are over 80% for all five features. The highest rate of agreement is 97.2% for TH stopping/fronting, followed by L vocalization (94.5%); CCM (93.9%); /r/, /v/, /w/ substitution (89.9%); and lastly, [n, l]/[s, ʃ] conflation (81.9%).
| TH Stop./ Front. | L Vocal. | [n, l]/[s, ʃ] Conf. | /r/, /v/, /w/ Subst. | CCM | |
|---|---|---|---|---|---|
| % Agreement between Raters | 21/730 97.2% |
20/359 94.5% |
4/22 81.9% |
5/49 89.8% |
20/325 93.9% |
After ensuring the inter-rater agreement on the occurrence of each feature, the number of word tokens to be analyzed were calculated in the following way. First, the total number of words including fillers such as um, uh, and eh were counted. The total word count (fillers included) is 6,325. However, as fillers are not exactly words and do not have much phonological features for investigation, it was concluded that fillers would not be considered in the analysis. Therefore, the number of fillers were counted and in total, there are 534 fillers. Then, by deducting the number of fillers from the total word count, the number of word tokens that would be actually analyzed were calculated. In total, 5,791 word tokens were taken into consideration in the analysis. Table 3 gives an overview of the total word count (fillers included), number of fillers, and total number of actual word tokens that were analyzed.
| Total Word Count (Fillers Included) | 6,325 |
| Number of Fillers | 534 |
| Number of Word Tokens Analyzed | 5,791 |
The analysis showed that there is a significant difference in the prevalence of the five consonantal features. Similar to the findings in Sewell & Chan (2010), the present data shows that phonemic substitutions (/r/, /v/, /w/ substitution) and conflation ([n, l]/[s, ʃ] conflation) were the least used by the speakers. Whereas, the most commonly used features are TH stopping/fronting, followed by L vocalization and CCM. As shown in Figure 1, the distribution of the five consonantal features used by the speakers is not quite even and there is a noticeable contrast between them. All of the speakers (100%) used TH stopping/ fronting and CCM in their speech, and over 90% of the speakers used L vocalization, whilst only 55% of the speakers used phonemic substitution and 25% of the speakers used conflation.
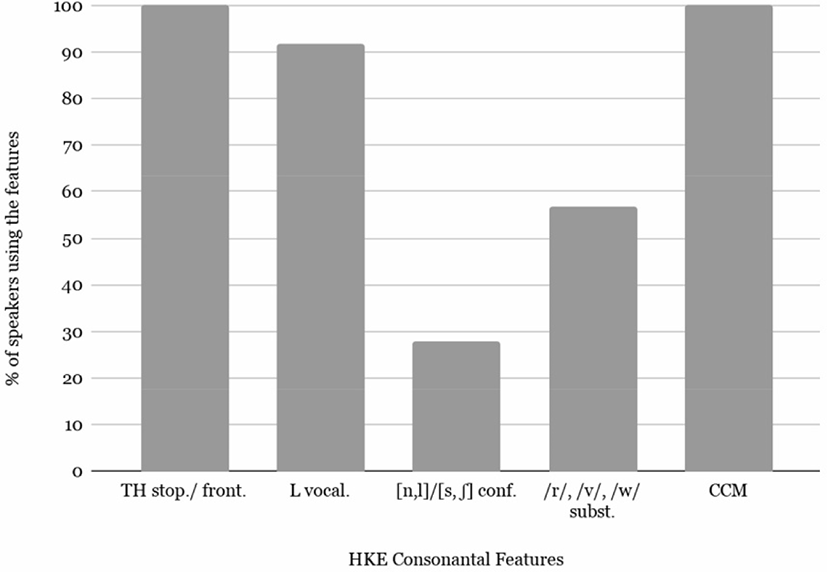
Table 4 provides a more detailed display on the distribution of the five consonantal features. Even though as stated earlier, both TH stopping/fronting and CCM were used by all 29 speakers, the number of word tokens with such features and their frequency of occurrence actually differ. Considering the frequency of occurrence, there is in fact a noticeable difference between TH stopping/fronting and CCM. As shown in Table 4, the frequency of occurrence of TH stopping/fronting is 12.6%, whereas that of CCM is only 5.6%. This is similar to the situation of L vocalization. For L vocalization, the percentage of speakers having this feature is rather high (91.9%); nevertheless, its frequency of occurrence is comparatively low (5.7%). This reflects that although all these three features are the most common considering the number of speakers using the features, this is not the case when considering the actual occurrence in the mini-corpus. Regarding the frequency of occurrence, TH stopping/fronting is the most frequently occurring in the mini-corpus, at almost double the frequency of occurrence of CCM and L vocalization.
In the following five subsections, each of the consonantal features will be discussed in detail regarding their usage by the speakers in our data. In order to provide an accurate demonstration, examples extracted from the transcripts will also be presented, adopting the methods of Deterding et al. (2008) and Setter et al. (2010), with only the concerned features shown.
As mentioned in Table 1, TH stopping/fronting refers to the substitution of voiced and voiceless dental fricative /ð/ and /θ/ with [d] and [f], respectively. The current data shows that TH stopping/fronting is the most frequently occurring feature among the five selected HKE features. The occurrence of TH stopping/fronting is the highest in general, whether it is regarding the number of word tokens with the feature (730), the percentage of frequency of occurrence (12.6%), or the percentage of speakers using the feature in at least one context (100%).
TH variation in HKE has been investigated by researchers, and the focus has been mostly on TH fronting, which is considered to be “a distinguishing feature of HKE in contrast to other varieties of Asian Englishes” (Hansen Edwards 2018: 443). It is widely observed that voiceless TH is sometimes pronounced as [f] in HKE (Luke & Richards 1982, Bolton & Kwok 1990, Hung 2000, Deterding et al. 2008, Hansen Edwards 2018), and the present data echoes these previous studies. It can be seen from the data that all the 29 speakers used [f] to replace the voiceless TH sound in at least one context. Similar to the findings in Deterding et al. (2008), the present data shows that voiceless TH occurs the most in its initial position, followed by the medial position, and then the least in the final position. However, regardless of their positions, in most cases from the present data, the voiceless TH was replaced by [f]. Apart from TH fronting, the present data also shows a fairly significant amount of TH stopping. TH stopping refers to the replacement of the voiced dental fricative /ð/ with [d]. From the data collected, it was found that all 29 speakers used [d] to replace the voiced TH sound in at least one context. As with TH fronting, the most common position of voiced TH sound is the initial position, followed by the medial position, with the least being in the final position. For most of the voiced TH sounds in the present data, they were replaced by [d], particularly when it is in the initial position or medial position. However, it is found that /ð/ was sometimes replaced by [f] but not [d]. For example, in extract (1) and (2), the word with /wɪð/ was pronounced as [wɪf], in which the voiced TH sound was replaced with [f] but not [d].

Furthermore, it is found that the word tokens having the feature of TH stopping/fronting are primarily function words. The most frequently occurring word with this feature seems to be the determiner the. Generally speaking, there are a rather large number of determiners with TH stopping/fronting, such as the, that, their, and another. There is also a large number of pronouns like they and conjunctions such as otherwise and whether:

On the other hand, there are much less word tokens found to have TH stopping/fronting that are content words. A few examples of content words with the feature are think, three, authority, gathering, etc.:

Due to the fact that the audio clips are from unscripted interviews, it is possible that the speakers used more function words in their speech than content words. It is also possible that this is simply because there are more function words than content words, and as Bell et al. (2009) mentioned, the pronunciation of content words and function words differ in conversational speech. Doubtlessly, the limited amount of data in the current study cannot be used to draw a definite conclusion as to why TH stopping/fronting occurs in function words more than in content words. Nevertheless, the relationship between TH stopping/fronting and word groups could be further investigated in the future.
L vocalization is also a very obvious and common feature of HKE, particularly when it is at the end of the syllable (Setter et al. 2010). According to Deterding et al. (2008), L vocalization generally refers to the “use of a vowel in place of dark [l]” (p. 161). However, Hung (2000) also indicates that sometimes deletion of [l] occurs rather than replacement of it. In the present data, both [l]-deletion and vowel replacement were found. L vocalization is the second most frequently occurring feature among the five targeted HKE features. Even though the frequency of occurrence of L vocalization is significantly lower (5.7%) than TH stopping/fronting, L vocalization is still counted as a rather frequently occurring HKE feature. Among all the speakers, 91.9% of them used L vocalization in their speech. This shows that L vocalization is a common HKE feature, at least among the HKE speakers sampled in this study.
In the present data, L vocalization was found to occur in both word-final position and preconsonantal position. This echoes Sewell & Chan (2010), in which L vocalization was also found in both positions. Among all the word tokens with L vocalization, most of them are of vowel substitution. Also, most of the cases are when [l] is in a word-final position, such as example, will and people:

Regarding [l] deletion, there are significantly fewer incidences from the present data. Unlike vowel substitution, which was found in mainly word-final positions, [l]-deletion was found in both medial and word-final positions. A few examples of words with [l]-deletion are railways, upholding, call, fall, etc.:

[L] vocalization is an extremely common feature among many varieties of English, including Singaporean English and even some varieties of British English like Estuary English (Deterding et al. 2008). This leads to the suggestions that vocalization of [l] might become standard soon (Wells 1982). It is possible that HKE is “at the forefront of the development of the language in extending the deletion of [l] after a back vowel to words in which it is in final position” (Deterding et al. 2008: 161). Nevertheless, the occurrence of [L] vocalization in HKE could also be related to L1 transfer. According to Chan & Li (2000), even though there is /l/ in Cantonese, it only appears in word-initial position such as 來 “come” /lɔi/. On the other hand, /l/ can be in both word-initial and word-final positions, and even the medial position, as the present data shows. In the next section, potential L1 transfer of [L] vocalization will be discussed in further detail.
Conflation of two consonants means that the two consonants are in free variation in the onset position. In this study, two groups of conflation were considered, including [n, l] and [s, ʃ] conflation. The conflation of [n] and [l] in the syllable onset has been widely discussed by numerous researchers; it is found that this feature is not common to all HKE speakers and that its occurrence is “not entirely predictable by rule” (Setter et al. 2010). The data collected in this study echoes Setter et al. (2010). The occurrence of both [n, l] and [s, ʃ] conflation is rare in the data, with the lowest percentage of frequency of occurrence (0.3%) and only 11 speakers having this feature.
In the current data set, [n, l] conflation occurs more frequently than [s, ʃ] conflation, despite the fact they are both rare. There are no rules or patterns observed from the data in how the consonants are conflated. As Hung (2000) suggests, conflation is a free variation, and so, it is rather difficult to observe a rule out of it. In some cases, /l/ is produced as [n]; and in other cases, /n/ is produced as [l]. The present data set shows that the number of cases of /l/ being produced as [n] and vice versa are rather similar:

As for [s, ʃ] conflation, it is difficult to conclude if it is a free variation or not due to the limited number of instances found in the current study. Only a few instances of /ʃ/ being produced as [s] were found in the data set:

Even though [n, l] and [s, ʃ] conflation seems to be unpredictable among HKE speakers, it could still be argued that there is influence of Cantonese, which leads to this feature. According to Setter et al. (2010), there is a “well-documented /n/-/l/ merger that is taking place in Cantonese” (p. 21). It is possible that the /n/-/l/ merger in Cantonese affects how HKE speakers produce /n/ and /l/ in English, and this issue will be discussed further in the next section.
As mentioned in Table 1, /r/, /v/, /w/ substitution refers to the phenomenon where the three consonants are pronounced interchangeably in any word position. Similar to the findings in Sewell & Chan (2010), this feature is comparatively less common among the five selected HKE features in the present data set. The frequency of occurrence of this feature in the data set is only 0.9%. However, it is worth noting that unlike Sewell & Chan (2010), in which less than 20% of the speakers had /r/ or /v/ substitution, in the current data set, nearly 60% of the speakers showed this feature. This reflects that /r/, /v/, /w/ substitution is fairly common among the HKE speakers, at least among those analyzed in the current study.
In the data set, /r/, /v/, /w/ substitution was found to be in both word-initial position and medial position. For example, substitution of /r/ with [w] was found in words such as coronavirus, previously, etc.; and substitution of /v/ with [w] was found in words including invoked and very. Among all the analyzed tokens, most of the cases are /v/ being realized as [w]. There are also a few incidences where /r/ is being realized as [w], but there is no realization of /w/ as [r] or [v] found in the data set:

The reason for this feature being relatively common in HKE speakers can be related to L1 transfer. It is said that both /r/ and /v/ are absent in Cantonese (Chan & Li 2000, Matthews & Yip 2011). However, in Cantonese, there is /w/, which is also in the English consonant inventory. Particularly in Cantonese, there is /gw/, which is similar to the English /gr/ consonant cluster. Therefore, it is possible that HKE speakers are more familiar with the consonant /w/, and so when they encounter /r/ and /w/, which are absent in their L1, they substitute with a similar and familiar consonant /w/. In the next section, more details on possible L1 transfer on this feature will be discussed.
As mentioned earlier in Table 1, CCM refers to the modification of consonants clusters, including both initial and final clusters. In the current study, both initial and final CCM were considered and grouped together as one feature. CCM is found to be one of the three relatively common features among the five features in the study. Even though the frequency of occurrence seems low (5.6%), in fact all 29 speakers in this study showed CCM and 325 tokens were found to show CCM. Initial and final CCM were found to be equally frequent among the speakers. In some rare cases, both initial and final CCM could be found in the same word token:

According to Setter et al. (2010), consonant clusters are often simplified, as it is “uncommon for syllables to end with clusters of more than two consonants” (p. 18). This shows that CCM is a rather common feature in HKE and it is very likely the result of L1 transfer. In fact, this is a universal feature among second language users (Nguyen & Dutta 2017). Due to the absence of consonant clusters in Cantonese, HKE speakers will “tend to use deletion or epenthesis” (Chan & Li 2000: 81) in order to cope with consonant clusters in English. In the next section, L1 transfer on CCM will be discussed in more detail.
On the other hand, there is a possibility that grammar also plays a part in CCM. For example, as seen in extract (35) and (36) above, CCM was found in the words traced, stopped, and searched, which are all in past tense. Therefore, it is expected to see that they are produced with consonant clusters to indicate the tense. However, as seen in the extracts, the consonant clusters were omitted in the verbs. As much of the previous literature indicates, L1 transfer does play a role in L2 acquisition of English grammar. According to Hawkins & Liszka (2003), L2 speakers of English from certain L1 backgrounds, including Chinese, “show persistent optionality in marking thematic verbs for simple past tense in spontaneous oral production” (p. 21). They argue that Chinese speakers have difficulty in assigning past tense, “which determines the morphophonological forms of verbs in English” (Hawkins & Liszka 2003: 24), because in Chinese, there is no such feature. Similar to Mandarin Chinese, in Cantonese, there is no syntactic change in verbs in past tense. Even though Cantonese does have a way to indicate past tense, it is different from English, where for most of the time, a suffix will be added to a verb to indicate the tense. Therefore, it is possible that the speakers in extracts (35) and (36) simply forgot to add the suffix -ed to the verbs to indicate past tense, rather than showing the phonological feature of CCM.
5. Discussion
In the previous section, it is shown that the current study confirms the findings of a number of previous studies on the commonness of the HKE consonantal features, which helps answer the first research question. Here in the discussion, the two other research questions will be answered with the help of the findings. Also, contrastive approach and L1 transfer will be discussed based on the findings in the following two parts.
-
HKE Features in Contrastive Approach Hypotheses (CAH) Under the world Englishes Paradigm
-
HKE Features and the Hong Kong English Continuum
To initiate a CAH between English and Cantonese, the contrast between the consonantal inventory is needed for the discussion. From the findings above, an up-to-date contrast between Cantonese and English has been summarized in Table 5.
From the table, it can be seen that several major differences between Cantonese and English are labio-velar stops (/kʷ/ and /gʷ/), dental fricatives (/θ/ and /ð/), post-alveolar fricatives (/ʃ/ and /ʒ/), alveolar affricatives (/ts/ and /tz/), post-alveolar affricatives (/tʃ/ and /dʒ/) and post-alveolar approximant (/ɹ/). Matthews & Yip (2011) argued that the major contrast between stops in the two languages is in fact the aspiration—instead of voiced and voiceless differences (e.g., /b/ and /p/, /t/ and /d/, /k/ and /g/ in English), the difference in Cantonese is aspirations (e.g., /p/ and /pʰ/, /t/ and /tʰ/, /k/ and /kʰ/, /kʷ/ and /kʷʰ/ in Cantonese). However, since most of the previous literature referred to voicing difference instead of aspiration difference, this current study will still focus on voicing difference in this regard. For the two dental fricatives, even though Hung (2000) suggested that they may be absent in the consonant inventory of HKE, a more recent study done by Hansen Edwards (2018) argued differently. In Hansen Edwards (2018), the voiceless dental fricative /θ/ was found to be used by nearly half of the 44 Cantonese-English bilingual participants. This shows that /θ/ may somehow be an emerging phoneme among some Hongkongers. Hansen Edwards’ (2018) result is further confirmed by Chan’s (2020a) research. In Chan (2020a), incidences of dental fricatives were found to be dependent on individual speakers among the eight samples of Hongkongers, which echoes what Stibbard (2004) mentioned, that the occurrence of /θ/ is speaker-dependent among Hongkongers.
From the present study, it seems that three of the chosen features, TH-fronting/stopping, [n]-[l] or [s]-[ʃ] conflation and /r/-/l/-/w/ substitution), are accountable under the CAH analysis. First, for TH-fronting/stopping, which contributes to more than half of the total tokens (729 tokens) and appeared among all speakers, the use of [f] to replace /θ/ (fronting) and [d] to replace /ð/ are shown to be a common feature among Hongkongers. Since dental fricatives are said to be uncommon among languages (Jung 2004) and are absent in Cantonese, the speakers tended to use another sound, which is close in the place of articulation and is a labiodental fricative /f/ from the mother tongue as a replacement. However, the same could not apply to /ð/ as voiced labiodental fricative /v/ is also absent in Cantonese—instead, [d] is used as a substitution for /ð/, as it is the closest voiced sound with the same place of articulation. TH-fronting/stopping is common among the pan-pacific region, such as, for example, China (Deterding et al. 2008), Singapore, and Malaysia (Phoon et al. 2013), and even for the younger generation of British teenagers (Drummond 2018). However, it is also interesting that different places have a different preferred variant to replace dental fricatives, while [t] is common for Singaporean and Malaysian, [s] is common for mainland Chinese (Hansen Edwards 2018). The reason why Hongkongers use [f] as a substitute instead of [s] or [t] is still unclear. However, there are also incidents in the current study that speakers use [s] to replace /θ/:

The example may be an extremely rare case, as the frequency of occurrence in the database is really low (only 1). It may be an incident of a slip of the tongue. Nonetheless, this rare finding is coherent with what Hansen Edwards (2018) found in her 1,700 data, that only 5% of TH-sounds in her 1,700 data was realized as an [s] sound. The same was also found in Chan’s (2020a) research, in which only 1 out of 8 speakers used [s] to replace TH sounds in “Think” [sɪŋk] (p. 102). More importantly, in all the above cases, it seems TH is also used in a variation along with TH sounds or [f], as the same speaker may use [s], [f] and TH sounds in the same speech, which is somehow in a free-variation pattern.
The second feature, [n]-[l] or [s]-[ʃ] conflation, is a surprising finding that contradicts with previous studies in different ways. To begin with, [n]-[l] conflation, unlike TH-fronting/stopping, which is initiated by the absence of the corresponding sounds in Cantonese, both /n/ and /l/ exist in English and Cantonese. However, Hung (2000) suggested that /l/ and /n/ are in “free variation” from his samples of 15 Hongkongers (p. 352). Among the speakers in Hung (2000), one-third of them either use [l] to substitute /n/ or vice versa. Setter et al. (2010) also agreed that the conflation between /n/ and /l/ seems to be unpredictable among Hongkongers. However, from a CAH perspective, it seems that Cantonese does play a role in this conflation. To et al.’s (2015) experiment of 112 Hongkongers discovered that Hongkongers tended to merge /n/ and /l/ in Cantonese, which is seen as a language change specific to Hong Kong. Since /n/ and /l/ in Cantonese move closer to each other in the Cantonese inventory, it surely brings an impact to English as an example of L1 transfer. Whether /n/ and /l/ are in free variation, the data from the current study is still lacking, as the number of incidence is really low (0.3% of the data) and only 28% of the speakers showed these features. Among them, conflation from /n/ to [l] accounted for six incidents while from /l/ to [n] accounted for four. The insufficient data here seems to leave this question open for further experiment in the future. For the conflation of /s/ and /ʃ/, among the very limited literature, Munro & Derwing (2006) reported a conflation of [s] and [ʃ] in the initial position. However, this type of conflation was found absent in Sewell & Chan’s (2010) database. In the current study, similar to [n]-[l] conflation, only a small number of [s]-[ʃ] conflation was found (seven incidences). Different from what was suggested by Munro & Derwing (2006), the cases here included both initial and medial position in a word:

Even though the number of incidents are limited, it can still be seen from the data that this conflation could occur in either /s/ to [ʃ] or /ʃ/ to [s]; nevertheless, the data only shows the interchangeability between /s/ and /ʃ/ in the initial position (e.g., shortcoming #32), while in the medial position, only /ʃ/ to [s] was spotted (e.g., precautionary #37, international #37). Although the number of cases may not reflect a full picture, it provides initial data for this feature for further study as well.
At last, for /r/-/w/-/v/ substitutions, the current data provides additional information to complement the existing important literature, which is scarce. The studies of the use of /r/, /v/ and /w/ in HKE started from Hung (2000), in which he concluded that “there is no phoneme /v/ in HKE” (p. 350), which leads to the substitution of /v/ using [w]. In Sewell & Chan (2010), both /r/ and /v//w/ were reported to be replaced by [w] in the onset position. The current study showed that using [w] to substitute /r/ and /v/ is common; among the 29 speakers in the study, nearly 60% of them showed the substitution of this kind. Despite the low number of incidences (0.8% of the database), the data set showed more [w] substitution for to /v/ (87.8%) than /r/ (12.2%). Examples from both substitutions in initial and medial positions were also found in the data set, which are different from Chan & Li’s (2000) study, in which they mentioned the substitution of [w] for /r/ was only in the word-initial position.

The use of [w] as a replacement for /r/ and /v/ is sensible as a result of L1 transfer since /r/ and /v/ are both said to be absent in Cantonese (Chan & Li 2000, Matthews & Yip 2011). In the case of having a consonant from the target language that does exist in the mother tongue, “The substitution by a near sound in the native language seems to be the most common strategy used [by speakers]” (Chan & Li 2000: 79). Sewell & Chan (2010) also came to a similar conclusion that “/v/ and /r/ substitution, and the conflation of [n] and [l], are probably related to transfer from the L1” (p. 153). The word Great is an interesting incident, as the consonant cluster in English /gr/ is modified to [gw], which is a Cantonese consonant. It is an example that is rare in the current literature and it is hopeful that it initiates further studies on the substitution of this sound. The same also goes with L vocalization and CCM, as Setter et al. (2010) mentioned that there has been “well-documented /n/-/l/ merger that is taking place in Cantonese” (p. 21) and Hawkins & Liszka (2003) stated that speakers whose L1 is Chinese normally have difficulty in assigning past tense, “which determines the morphophonological forms of verbs in English” (p. 24).
The above examples showed that the way Hongkongers speak HKE is highly related to the mother tongue, Cantonese. In the traditional CAH, the conclusion would generally be drawn by defining these features as “errors” and teachers have to pay attention to tackle these in their classroom practices. For example, Chan & Li (2000) concluded their study with a statement that they believed the errors should be corrected because the errors may affect the intelligibility:
A heightened awareness of the contrastive differences between the two phonological systems will be helpful at least to some extent in facilitating the overcoming of the pronunciation problems… Teachers should also determine the relative gravity of various pronunciation errors and set up a system of teaching priorities. We believe that pronunciation errors which affect intelligibility or create communication problems should be given priority in remedial teaching (p. 83).
However, a primary question here is whether these HKE features really affect the intelligibility of HKE. Under the paradigm of world Englishes, features of different varieties of Englishes are examined and valued as the result of language contacts. Whether the varieties of English carry certain features may not be the major focus; instead, the more important part is whether the feature is intelligible to listeners worldwide.
The intelligibility of HKE to different listeners has been investigated for decades, and the results in general showed that HKE is highly intelligible inside and outside the Asia region. To be specific, the intelligibility of HKE has been found to be high to various listeners from different places, for example, Singapore and Australia (Kirkpatrick et al. 2008), Japan (Matsuura 2007), China, and United States (Hansen Edwards et al. 2018). In Hansen Edwards et al.’s (2018) study of the intelligibility of four varieties of English—including American English, China English, Singaporean English and HKE—HKE was found to have the highest intelligibility among the four to 92 listeners from the four respective places, some even higher than American English, the traditional inner-circle variety of English. Chan’s (2020a) study also showed a similar result that, among the 80 listeners from 18 countries, HKE showed a high intelligibility to most of them. Therefore, the question is: Will these features affect the intelligibility of HKE? To answer this question, Chan’s (2020a) HKEC may help in the future to tackle this (Figure 2).

Speakers were put along the continuum according to the number of HKE features they have. However, the more features they possess does not mean the more unintelligible they are. The continuum on one hand categorizes the speaker with the number of features, and on the other hand, it avoids using an exonormative form of English to measure a variety of English (e.g., the use of British/American English as “non-HKE” in Zhang 2014), which theoretically should stand alone because of its unique cultural and social contexts. Therefore, to complement the continuum, there should be studies to examine the effect on intelligibility on each of the features. Previous literature seldom isolates certain features from a given variety for intelligibility tests. Most of the previous studies take the variety as a whole, which in turn, makes it difficult to discover which features create more difficulty to listen to, or in other words, have more serious effect on intelligibility. In Chan (2020a), it was found that conflations between [n]-[l] and [w]-[v] may have a high effect on the intelligibility. Even though the current study does not focus on the intelligibility, the low number of [n]-[l] and [w]-[v] conflations may indicate that these are more serious, yet less common, features in HKE. Given the low number of incidents, it is safe to say that they may not be a common feature in HKE. Yet, it is important to note that due to the limitation in the current study, more should be done in the future for the intelligibility of each feature.
6. Conclusion
The current study has a number of implications on different aspects to the fields of studies, particularly to ELT and world Englishes. The current study explores the consonantal features of HKE among various speakers using online resources. The findings confirmed several previous studies and also provided new evidence for some types of features that have rarely been reported. The new findings consolidate the study of HKE phonetics and phonology. The study of the features of new varieties of Englishes is important, as it potentially offers implications for classroom pedagogies in ELT. As mentioned in the discussion, if intelligibility is the ultimate goal for students, regardless of the presence of unique features, there should be pedagogical implication to the ELT protocols in traditional classrooms, especially when the one in Hong Kong is typically exonormative-oriented (Sung 2015). Sakaria & Priyana (2018) mentioned that the use of a language that is familiar for the students to teach can actually enhance their learning. This is also coherent to the belief in world Englishes, which appreciates the differences in varieties. Chan (2020a) mentioned that the use of local features in teaching may help students in learning more effectively, and the use of HKE has been reported to be pedagogically valid in classrooms (Sewell 2012, Sung 2015). The question of whether using local varieties in classrooms is appropriate should be investigated as well. Moreover, the current study tries to use CAH under the world Englishes paradigm, which has rarely been done before. While the conventional CAH sees varietal features as “errors” and requests that teachers correct them according to the exonormative norms through classroom practices, the CAH in this study stresses only the reasons for having such features, mostly from L1 transfer of the mother tongue. Whether or not teachers should see these features as “errors” should be based on the intelligibility of such features. If some of the features in the local variety are mostly intelligible, there is no need to change them. As Chan (2020a) and Hansen Edwards et al. (2018) suggested, since the intelligibility of HKE may potentially be influenced by some of these features, further investigation is needed in the future, especially on each of the individual feature to examine their effects on intelligibility separately.
Needless to say, there are a number of limitations in the current study despite the fact that it has already overcome some of the limitations set by previous studies. The source of data is the major limitation to the current study, since the sound clips that are included did not cover a wide enough range of participants, including age, education, and features. However, the current study did already balance the gender as well as collected participants from different sectors and education backgrounds, which were not considered in previous studies. One of the problems with collecting data from the Internet is that those who would appear on the Internet are most likely people working in certain industries and with particular levels of education. Also, as Jewitt (2012) mentioned, the use of video as data may only show the fact partially because of the potential editing and the lack of facial cues. Nonetheless, Jewitt (2012) pointed out the advantages of using video data in research to provide an extensive pool of data with limitless numbers of participants, regardless of the geographical constraints. In the current study, researchers extracted data only from the Q&A sessions in press conferences, which were mostly simultaneous responses from the speakers. Thus, the data was hopefully unedited and more authentic. Another limitation relates to the quality of the sound samples. Since the content in the videos was uncontrolled speech, it is not possible for the videos to include all the linguistic environments that needed to be examined. However, with the limited number of features chosen and the higher amount of data in the current speech, it is also expected that the problem is lessened here. Truly, it is also recommended in the future for similar research to have a higher number of data that includes a diverse pool of participants and covers more linguistic environments.
To conclude, the current study serves to discover the consonantal features of HKE, with a CAH approach under a world Englishes paradigm. The five consonantal features that were investigated were found to be differently distributed among the samples. While TH-stopping/-fronting and consonantal modification were very common among Hongkongers, conflation of [n]-[l] or [s]-[ʃ] were also occasionally discovered. The contrastive analysis showed a possibility that L1 transfer accounted for three of them. A more important question is whether these individual features potentially affect the intelligibility of HKE; further studies are required in the future to answer this question. Also, with the examination of these features, the HKEC could be further fulfilled to indicate the commonness of features among the population of Hongkongers. More should be done on the discovery of these features and, as mentioned earlier, it should be determined how this affects ELT teaching in classrooms, which contributes to better learning for students. Along with the world Englishes paradigm, English is no longer solely based on an exonormative standard; instead, different standards from varieties have emerged and what scholars and educators should focus on is which are intelligible and thus, which should be taught to serve communication purposes as well as different cultural contexts.