




1. Introduction
Konkani is a southern Indo-Aryan language spoken chiefly in Goa, and by communities spread along the west coast of the Indian peninsula after the Portuguese colonisation. The centuries of contact it has had with other major languages on the west coast, namely Marathi, Kannada, and Malayalam, has given rise to several regional varieties.
The following vowel and consonant inventories of Goan Konkani are taken from Almeida (1989)’s texts (Table 1 and Table 2).
| Front | Central | Back | |
|---|---|---|---|
| High | i | u | |
| e | o | ||
| Mid | ɵ | ||
| ɛ | ɔ | ||
| Low | a |
All of the vowels in Table 1 can be nasalised. While Almeida (1989) shows phonemic distinction for /i/ and /i:/, /u/ and /u:/, and /a/ and /a:/, Miranda (2003) maintains that vowel length distinction has been neutralised in Goan Konkani.
A large majority of the Konkani data used in this paper is from the Konkani dialect spoken in central Kerala. The Central Kerala dialect of Konkani (henceforth referred to as Central Kerala Konkani [CKK]) has 38 consonant sounds. This includes 14 aspirated and breathy voiced stops, nasals, approximant and lateral, similar to Marathi. All the aspirated or breathy voiced consonants appear only word initially. However, they maintain distinction from their unaspirated counterparts. Except for these 14 consonants, all other consonants can occur in word-medial or intervocalic positions (Table 3).
CKK has the short vowels /i/, /u/, /e/, /ə/, /o/, /ɛ/, /ɔ/, and /a/, as shown in Table 4.
All of these vowels may also occur as long vowels. Whether the vowel length in Konkani, especially CKK variety is contrastive is not yet verified, as there are both instances of vowel length distinction as well as vowel length neutralisation.
All of the vowels in Table 4 also have their nasal counterparts. Nasalisation is a prominent feature of CKK and the oral and nasal vowels are in contrastive distribution. CKK also has six diphthongs: /ai/, /oi/, /əi/, /au/, /ou/, /əu/.
The Konkani language began spreading from Goa to the southern states of Karnataka and Kerala from the 16th century, due to the Portuguese colonization in the state. The attempt of the Portuguese to completely stop the use of Konkani by imposing the Portuguese language and destroying the existing literature in Konkani succeeded to some extent as it distorted the image of standard form, but at the same time such situation gives rise to various Konkani dialects, each influenced heavily by the languages they were in close contact with—Portuguese, Marathi, Kannada and Malayalam.
The dialect spoken in central Kerala vastly differs from those spoken in the North. While the northern dialects permit consonant clusters as well as codas, CKK follows the Malayalam syllable patterns more closely. Malayalam syllables prohibit codas (Mohanan 1982). In accordance with that, CKK speakers also tend to use open syllables and end their words with short vowels.
The paper has got six sections. Section 1 provides a brief introduction on Konkani language, its distribution and speakers with special emphasis on CKK variety. Section 2 discusses the syllable structure of CKK in detail especially with reference to syllable divisions, phonotactic rules that govern the syllabification process in this language. This section also highlights the repair strategies that CKK adopts in the case of loan words adaptation. Section 3 interprets this process of syllabification and breaking of the consonant clusters in this language in constraint ranking approach embedded in Optimality Theory (Prince & Smolensky 1993) in order to bring into fore the universal classical typology that governs the syllabification process in CKK. Section 4 shows the rules and patterns of word stress system in CKK which is quantity sensitive. Stress patterns in CKK appear to be different from other varieties of Konkani such as Goan Konkani. Section 5 highlights the stress system in CKK with reference to WSP and Edgemost constraints embedded in OT framework. Section 6 summarises the main findings of the paper.
2. Syllable Structure
The following are the possible syllable structures in CKK:

Out of these, CV and CVC are the most common syllable structures. The nucleus of the syllable is always occupied by a vowel. It may be a short vowel, a long vowel, or a diphthong. The Maximal Onset Principle (MOP), which states that consonants must be assigned to the onset position of the following syllable rather than the coda of the initial syllable, comes into play except when the language’s phonotactic rules disallow it. Under the OT framework, MOP can be defined to consist of the two constraints ONSET and NoCoda. The language’s preference to avoid consonant clusters is held over the MOP, as well as certain other rules, such as restrictions on onsets and codas. In VC and CVC structures of this language the codas are usually nasal sounds. Retroflex laterals also occur in the coda position and avoid the onset position. Table 5 below illustrates a few such examples:
| Konkani word | Gloss |
|---|---|
| am.bɔ | mango |
| ʋin.dʰu:ɭ.ɔ | swing |
| man.d̪u:.ɾi | mat |
| kãŋ.kəɳ.ə | bangle |
| əɭ.ʃi:.gə | disgusting |
| aŋ.gəɳ.ə | yard |
| bã:ŋ.ku | bench |
The Syllable Contact Law (Vennemann 1988) is also demonstrated here. The law states that syllable contact is preferred if the sonority of the offset of the first syllable is greater than the sonority of the onset of the following syllable. This means that sonority must fall from the coda of the first syllable to the onset of the second. The sonorants, i.e., the nasals and lateral that occur in the coda position are higher on the sonority scale that the obstruents, i.e., the stops or affricates which are the most common occupants of the onset positions.
These days, due to high exposure to various other languages, most Konkani speakers retain the consonant clusters in borrowings or loan words. However, several loan words which have been integrated into the language a long time ago have undergone phonological changes to fit phonotactic rules of Konkani. Let us look at a few such words that have been borrowed from Sanskrit, in Table 6:
| Sanskrit | Konkani | Gloss |
|---|---|---|
| ʃɾa:p | ʃi.ɾa:.pu, ʃa:pu | curse |
| d̪ɾa:kʃ | d̪ə.ɾa:k.ʃi | grapes |
| sʋəɾɡ | soɾ.ɡu | heaven |
| ʃɾa:.ʋəɳ.ə | ʃiɾ.ʋəɳ.ə | Shraavan – name of a month |
| sʋa:d̪ | su.ʋa.d̪u | taste |
The above Sanskrit words all contain a consonant cluster in the onset of the syllable. In order to adapt to the phonotactic rules of Konkani, they undergo the phonological processes of vowel insertion—prothesis or epenthesis—to break the consonant clusters.
Few studies on other dialects of Konkani (Almeida 1989, Peterson 2011, Vernekar 2017) show the presence of the CVCC structure. However, speakers of CKK tend to add a short vowel (usually /ə/ or /u/) to the end of such words, resulting in resyllabification. For example, the CVCC words t̪ɔ̃:ɳɖ ‘mouth’ and bəɾp ‘letter’ are realized as t̪ɔ̃:ɳ.ɖə and bəɾ.pə respectively.
The single syllable word ʃɾa:p ‘curse’ is of the structure CCVC. Two vowel sounds are added to modify it to a more acceptable CV.CV.CV structure, ʃiɾa:pu. It is interesting to note that this word can also be modified by deleting the /ɾ/ sound as well. This gives the word ʃa:pu, of the CV.CV structure. The two versions of the word are used almost interchangeably by Konkani speakers. However, ʃiɾa:pu can also be used as a verb, whereas ʃa:pu must assume a light verb construction instead.
Similarly, d̪ɾa:kʃ ‘grapes’ and sʋəɾɡ ‘heaven’ are both of the CCVCC structure. They also undergo different phonological processes and change to the more acceptable CV.CVC.CV and CVC.CV structures, as d̪ə.ɾa:k.ʃi and soɾ.ɡu respectively.
The word ʃɾa:ʋəɳ ‘Shraavan (name of a month)’ which is of the CCV.CVC structure modifies to ʃiɾ.ʋəɳ.ə, i.e., the CVC.CVC.V structure instead.
Besides vowel insertion, there are other ways of modifying the syllable structure, such as deletion of consonants. Consider the following examples in Table 7:
| Sanskrit | Konkani | Gloss |
|---|---|---|
| d̪ɾɪʂʈɪ | d̪ɪʂʈɪ | vision |
| t̪riɳə | tə:ɳə | grass |
| mu:t̪ɾ | mu:t̪ə | urine |
| put̪ɾ | pu:t̪u | son |
In the above examples, the phoneme /ɾ/ is simply deleted in order to remove the consonant cluster and hence make the words follow the phonotactic rules of Konkani.
While clusters with two consonants can sometimes be found in the coda positions of syllables in Konkani, clusters with three consonants are hardly found. The monosyllabic Sanskrit word of the structure CCCV st̪ɾi: ‘woman’ undergoes prothesis and epenthesis and is modified to ost̪əɾi, which is a trisyllabic word of the structure VC.CV.CV.
Similarly, older speakers of Konkani tend to use similar repair strategies on borrowings from English. For example, the word sku:l ‘school’ will be modified to isku:ɭə. Such repair strategies of epenthesis in loan word adaptation are also visible in the realm of loan word phonology. Epenthesis seems to be the preferred strategy to repair the onset clusters in many languages which is evident from the previous research such as Burmese (Chang 2009), Shona (Uffman 2006), Vietnamese (Nguyen & Dutta 2017), Japanese (Shoji & Shoji 2014), Persian (Ghorbanpour et al. 2019). Such evidence of epenthesis adopted as repair strategy at a cross linguistic level strengthens the notion of phonological strength that tries to capture the predominance of certain phonological features and units in the world languages. Dutta (2012) brings to fore the fact that phonological strength relations can play a crucial role in the patterning of phonological features not only in areas pertaining to language acquisition, pitch accent patterns and tonal phenomenon but also in loan word adaptation.
3. Syllable Structures in CKK and Constraint Ranking Approach
Following the changes in the words discussed in the previous section, we can arrive at certain conclusions about the phonotactics of the language, which can be subsumed under constraints. With the constraint ranking approach within OT, we can account how uniform set of constraints can better represent the phonological adaptations at the syllabic level of a language.
First, consonant clusters are discouraged in the onset position. This can be explained by the constraint *ComplexONS (Prince & Smolenksy 1993).

Second, we can see that a short vowel is added to all words ending with a consonant. This means that codas are prohibited. The NoCoda constraint (Prince & Smolenksy 1993) serves this purpose, as it means that no coda is allowed, leaving syllables open.
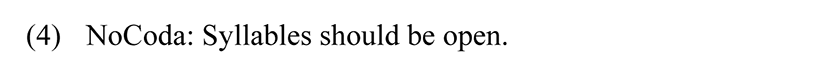
Furthermore, the faithfulness constraints MAX-IO and DEP-IO are present. MAX-IO ensures that no sound is deleted, whereas the DEP-IO constraint checks that no sound is inserted. (McCarthy & Prince 1995).

In order to show how these constraints work to arrive at the optimal candidate, consider the following data in (7) and OT analysis in Tableau 1.

| ʃɾa:p | *ComplexONS | NoCoda | MAX-IO | DEP-IO |
|---|---|---|---|---|
| a. ʃɾa:p | *! | * | ||
| ☞b. ʃi.ɾa:.pu | ** | |||
| c. ʃɾa:.pu | *! | * | ||
| d. ʃa:.pu | * | * |
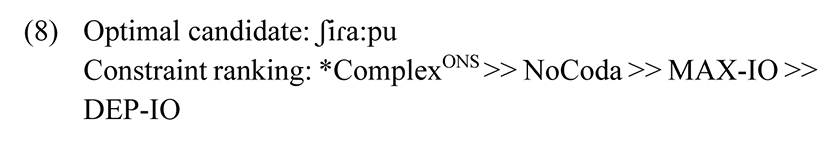
Candidate (a) and (c) fatally violate the *ComplexONSconstraint since they have a consonant cluster in the onset. Candidate (a) also violates the NoCoda constraint. While candidate (b) violates DEP-IO, it is a lower ranked constraint compared to MAX-IO, which is violated by Candidate (d). Therefore, (b) is the most optimal candidate.
Note: If the constraint ranking is modified to make DEP-IO a higher ranked constraint than MAX-IO, the optimal output will be ʃa:pu, as shown in Tableau 2 below.
| ʃɾa:p | *ComplexONS | NoCoda | DEP-IO | MAX-IO |
|---|---|---|---|---|
| a. ʃɾa:p | *! | * | ||
| b. ʃi.ɾa:.pu | ** | |||
| c. ʃɾa:.pu | *! | * | ||
| ☞d. ʃa:.pu | * | * |
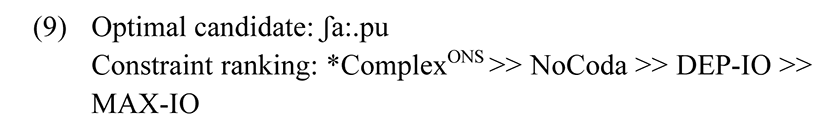
Candidates (a) and (c) gravely violate the higher ranked constraint *ComplexONS and are ruled out. Candidate (b) has two violations of DEP-IO while candidate (d) has a violation of DEP-IO and MAX-IO. However, since DEP-IO is the higher ranked constraint, candidate (b) is ruled out, and (d) is the optimal candidate.
Consider the following data in (10) for further illustration:

This example has a consonant cluster in both the onset and coda position. Both of the clusters are broken by epenthesizing vowels. Instead of using separate constraints prohibiting complex onsets and codas, we may use the *CC constraint, which prohibits two consonants appearing together.
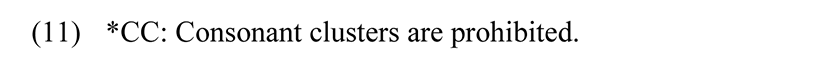
Consider the following Tableau 3 that displays the functioning of the *CC constraint.
| d̪ɾa:kʃ | *CC | NoCoda | DEP-IO |
|---|---|---|---|
| a. d̪ɾa:kʃ | **! | * | |
| b. d̪ɾa:k.ʃi | *! | * | * |
| c. d̪ə.ɾa:kʃ | *! | * | * |
| ☞d. d̪ə.ɾa:k.ʃi | * | ** |
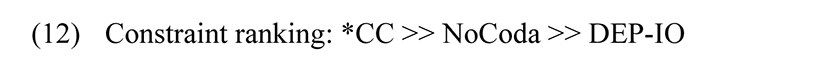
Candidate (a) has two violations of *CC since it has consonant clusters in both onset and coda positions, and it is ruled out. Candidates (b) and (c) also fatally violate *CC. All four candidates violate the NoCoda constraint. Even though candidate (d) violates DEP-IO, it is a lower ranked constraint, and (d) remains the optimal candidate.
Now, consider the following data in (13) which is an example of English loan in Central Kerala Konkani:

The consonant cluster may be broken by inserting vowels in the beginning, middle, or end of the cluster, and then resyllabifying the syllable. The Contiguity constraint says that no vowel should be inserted in the middle of the cluster.
Laterals in Konkani are distributed such that only alveolar laterals may occur in the initial positions and retroflex laterals usually occur in the final positions. The CodaCond constraint (Prince & Smolensky 1993) means that codas cannot license place features. Here, we can say that alveolar lateral is not allowed in the coda position due to it.
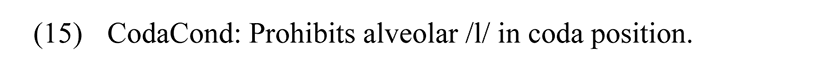
Consider the following Tableau 4 which displays the functioning of the constraint Coda Condition as a higher ranked constraint in CKK.
| sku:l | *CC | CodaCond | NoCoda | Contiguity | DEP-IO |
|---|---|---|---|---|---|
| a. sku:l | *! | * | * | ||
| b. sə.ku:l | * | * | * | * | |
| c. is.ku:l | * | ** | * | ||
| ☞d. is.ku:ɭ.ə | ** | ** |
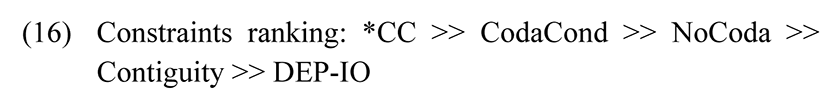
Candidate (a) is immediately ruled out as it fatally violates the *CC constraint. Candidates (a), (b), and (c) all violate CodaCond and NoCoda as their syllables all have codas and alveolar /l/ appears in the coda position, which is prohibited. Candidate (b) further violates Contiguity as well, as there is an instance of epenthesis in the word medial position. Even though candidate (d) violates NoCoda and DEP-IO, it has the least number of violations, and it does not violate the higher ranked constraints, making it the optimal candidate.
4. Word Stress in CKK: Generalizations and Rules
Similar to most other Indo-European languages, Konkani is not a tonal language, but it does have intonation and stress. Stress is a phenomenon where a syllable within a multisyllabic word appears more prominent than the other syllables. If we look at words in isolation, we can figure out the patterns of word stress. Let us consider the words in the following table.
In Table 8, the first three words are bisyllabic words with the first syllable being the more prominent syllable. These syllables need not be articulated with the same degree of prominence; stress is marked relative to the other syllables in the word only. The table allows us to conclude that bisyllabic words in CKK are stressed on the first syllable.
Let us then move on to the trisyllabic words. Here, we can see that aˈʋa:ɭ.o and koˈt͡ʃo:.lu, for example, has stress on the second syllable. However, ˈʋin.d̪u:.ɾu has its first syllable as the more prominent syllable. Therefore, from this information alone, we cannot come up with a rule for word stress. While we could claim that the length of the vowel decides the prominence of the syllable, where the stressed syllables in (5) and (6) contain a long vowel, this hypothesis will not stand true for (9), where the syllable with the long vowel is not stressed.
Therefore, another method is required to figure out which syllable is stressed. We shall be looking at the quantity of the syllable instead of vowel length. Quantity is measured by the number of segments in the rhyme of the syllable, excluding the onset. Here, we shall follow the moraic theory (Hayes 1989).
While defining the syllable structure of the language in the previous section, we had considered long vowels and diphthongs as a single V. However, long vowels and diphthongs contain two moras (µ) and postvocalic consonants, i.e., consonants in the coda position are also moraic. For this reason, we shall redefine the syllable structure, representing a long vowel or diphthong as VV instead.

Coming back to quantity, we can distinguish between the weights of the syllable as being heavy or light by looking at the number of segments in the rhyme. Monomoraic rhymes will therefore be considered light whereas bimoraic rhymes will be considered heavy.
To be clearer on the heavy-light distinction, let us define them as follows:

Now let us consider the following examples in Table 9, with the syllables and stress marked, the syllable structure, and whether they are light or heavy given. We can see that the heaviest syllable attracts stress. In words with more than one heavy syllable, the first heavy syllable is stressed.
The word stress or accentuation patterns of Indo-Aryan languages such as Hindi have been studied extensively. While stress placement rules differ in each case, the studies all follow the syllable weight method to place stress. Studies on word stress in Hindi by Mehrotra (1965) and Pandey (1989) both place the syllables into three categories based on weight: light (one mora), heavy (two moras) and superheavy (three moras). Pandey (2014) while discussing about Hindi prosody shows that in trisyllabic words the superheavy syllable is generally stressed. If there are two adjacent heavy syllables, then the right heavy syllable is stressed. If there are two adjacent light syllables, then the left light syllable is stressed. Unlike Hindi, stress placement in CKK is more towards the left edge when adjacent syllables have the same weight. Peterson (2011) describes stress placement in Goan Konkani. Similar to CKK, he creates a two-way distinction for the syllables as weak and strong. However, in the Goan Konkani dialect, when two strong or weak syllables come together, the rightmost syllable receives stress. This is also completely different from the Central Kerala dialect of Konkani.
5. Word Stress in CKK and OT Analysis
This section attempts to represent the stress system in CKK in OT framework. By examining the placement of primary stress on bisyllabic and trisyllabic words in the previous section, we have observed that stress falls on the heaviest syllable. If there are multiple heavy syllables, it falls on the leftmost heavy syllable. If there are only light syllables, it falls on the leftmost syllable. This can be translated into the following constraints (Prince & Smolensky 1993):
The heaviest syllable is the most prominent syllable.

The peak of prominence is on the leftmost syllable of the word.
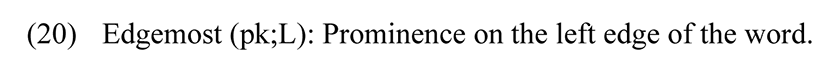
In order to display the dominance of the constraint WSP over Edgemost (pk:L) consider the following data in (21) and its representation in Tableau 5.
| ku.ʈi:.ke | WSP | Edgemost |
|---|---|---|
| a.ˈku.ʈi:.ke | *! | |
| ☞b. kuˈʈi:.ke | * | |
| c. ku.ʈi:ˈke | *! | * |
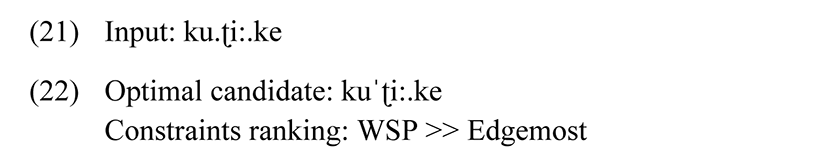
Candidate (a) and (c) violate WSP since they are stressed on light syllables. This makes the candidate (b) as the optimal candidate even though it has a violation of Edgemost.
For illustration consider the following data in (23) and its representation in Tableau 6.
| ʋin.d̪u:.ɾu | WSP | Edgemost |
|---|---|---|
| a. ʋinˈd̪u:.ɾu | * | |
| b. ʋin.d̪u:ˈɾu | *! | * |
| ☞c. ˈʋin.d̪u:.ɾu |

Candidate (b) fatally violates WSP as it is stressed on a light syllable. Candidate (a) and (b) both violate Edgemost (pk;L) as they are not stressed on the leftmost syllable. This makes the candidate (c) as the optimal candidate with no violations of both constraints.
6. Conclusion
This paper describes the syllable structure and its formation in CKK. The syllable structure is vastly different from other Indo-Aryan languages as well as other dialects of Konkani, in that it prohibits consonant clusters in both onset and coda positions and avoids closed syllables especially in the word final position by inserting a vowel at the end. While syllabifying, the onset and coda restrictions of the language are placed over the Maximum Onset Principle. The syllable contact law (sonority) is also intact here. Consonant clusters are broken by the repair strategy of deletion of consonants or insertion of vowels. These processes result in resyllabification of the word. Under the OT framework, the optimal candidates are a result of the resolution between the following constraints, ranked as *CC >> NoCoda >> DEP-IO. The word stress patterns also widely differ from those of the northern dialects. We have concluded that the primary accent in Konkani is placed on the heaviest syllable. However, in cases where a word has two heavy syllables or only light syllables, stress is on the leftmost syllable. This is explained by the constraints ranked as WSP >> Edgemost (pk;L).