




1. Introduction
Lexical comparison has gained a lot of attention in the field of linguistics. Arokoyo (2016a, 2016b), Bamigbade & Oloso (2016), Obisesan (2012) to mention just a few have worked in different areas of lexical comparison using different Nigerian languages and dialects. Moving outside the shore of Nigeria, scholars like Parkhurst & Parkhurst (2003), Castro, Flaming & Youliang (2012) have also worked in this area. Their study revealed how they compared the different languages they worked on using the comparative method and the lexicostatistics analysis approach to derive cognate percentage in order to determine the level of the dialects’ mutual intelligibility. Yoruba language, according to Arokoyo (2010: 8-9), ‘has very many dialects with varying degree of mutual intelligibility’. Even though a number of studies on lexical comparison have been done, no study has examined the level of mutual intelligibility in Yorùbá, Àkúrẹ́ and Ìkàrẹ́ Àkókó.
Based on Arokoyo’s (2010) claim that varying degree of phonological, lexical and grammatical differences are noted in the dialects of Yoruba, and Oyetade’s (2007) classification that Ìkàrẹ́ Àkókó belongs to the Yoruboid language of the varieties in Akokoland instead of the Akokoid varieties, this paper aims to fill such vacuum by determining the level of mutual intelligibility of Yorùbá, Àkúrẹ́ and Ìkàrẹ́ Àkókó based on their genetic classification i.e. if they belong to the same language family. This will help to examine their various linguistic features and resources and serve as a documentary data for future researchers. In the course of our research, there is paucity of works on lexical comparison in Standard Yorùbá, Àkúrẹ́ and Ìkàrẹ́, hence the need for this research work. The objectives of this study are to find out the areas of similarities and differences of the lexical items, their phonological relatedness and to determine the cognate percentage of relatedness of the three speech forms.
In this study, the lexicon of Yorùbá, Àkúrẹ́ and Ìkàrẹ́ Àkókó were examined. Six native speakers were used for this study; two native speakers of Àkúrẹ́, two native speakers of Ìkàrẹ́ Àkókó and two native speakers of Yorùbá. The data for this paper were collected using the SIL Comparative African Wordlist (SILCAWL) of basic lexical items in sessions of focus group discussions in the three locales. The researcher used a recording device to elicit the lexical data with the aid of the research instrument. The data were presented in a table which made it easy to identify the areas of similarities and differences of the dialects. This paper adopted a comparative method for the numeral analysis, animal and edible nouns and also presented the lexicostatistics analysis for the three dialects. The numerals were compared by looking at their formations and mathematical derivations and animal and edible nouns were compared by observing the sound alternations while the lexicostatistics analysis was done to derive the cognate percentage. Basic vocabularies and other related items from the three speech forms were considered and the following criteria were used to determine the lexical items that are similar and different:
-
Words are counted as similar if their pronunciations are identical barring only their tones.
-
Words with more than one syllable were counted as dissimilar if at least one of their component syllables is dissimilar.
-
Words that are different in forms but have same meaning are considered different words.
-
Derived words were seen as a case of compounding i.e. two separate morphemes combined to form new compound word.
-
Borrowed words that are different in forms are different words.
This paper is organised into six sections. The first section introduces the work while Section 2 gives a brief history of Yoruba, Ìkàrẹ́ Àkókó and Àkúrẹ́ dialects. In Section 3, we discussed the literature review. The fourth section examined the theoretical framework. The fifth section of the paper is the data presentation, analysis and the discussion of findings while the final section concludes the work.
2. History of Yoruba, Ìkàrẹ́ Àkókó and Àkúrẹ́ Dialects
Yorùbá is one of the three major Nigerian languages spoken in South-western Nigeria. According to Akinlabi & Adeniyi (2017: 31) ‘all the various tribes of the Yoruba nation trace their origin from a leader called Oduduwa and the city of Ile-Ife, in today’s south-western Nigeria’. Yorùbá is spoken by about forty million people in Nigeria and the diaspora (Eberhard, Simons & Fennig 2019). Yoruba has many dialects which differ from one another to a very large extent. We therefore see the diverse varieties of the Yorùbá language, used by groups smaller than the total community of speakers of the language within the geographical area, as dialects of the same language. Yoruba is a tone language and its basic word order is SVO (Ilori 2012).
There have been various classifications by scholars such as Adetugbo (1967), Oyelaran (1970), and Awobuluyi (1998). For the purpose of this study, we will adopt Adeniyi’s (2010) classification which is the most recent classification. He classified Yorùbá dialects into seven as indicated below:
-
Eastern Yorùbá (EY): Ùkàrẹ́, Ọ̀bà, Ṣúpáre, Ìdó-àní, etc
-
North-Eastern Yorùbá (NEY): Ìyàgbà, Ìjùmú, Owé, Ọwọ́rọ̀, Gbẹ̀dẹ, Ìkìrí, Bùnú, Àyèré
-
Central Yorùbá (CY): Ifẹ̀, Ìjẹ̀ṣà, Èkìtì, Àkúrẹ́, Mọ̀bà
-
South-Western Yorùbá (SWY): Èkó, Àwórì, Ẹ̀gbá, Yewa
-
Western Yorùbá (WY): Ànàgó, Kétu, Ifẹ̀ (Tógò), Ọ̀họ̀rí, Tsábeͅ, and other dialects spoken in other parts of the World
-
South-Eastern Yorùbá (SEY): Ìjẹ̀bú, Ìlàjẹ, Ìkálè̙, Òǹdó, Ọ̀wọ̀
-
North-West Yorùbá (NWY): Ọ̀yọ́, Òǹkò, Òṣun, Ìbọ̀lọ̀, Ìgbómìnà
Standard Yorùbá is regarded as the official language used in politics, schools, education, entertainment, media and it is also recognized by the government as a regional language. The Standard Yorùbá is the form that every Yoruba can speak and it serves as a common heritage of the Yorùbá people.
The Ìkàrẹ́ Àkókó people are also descendants of Odùduwà and migrated from Ilé-Ifẹ̀. Ìkàrẹ́ left Ìlàrẹ́ quarters in Ilé-Ifẹ̀ for Àkókó in the 18th century. Ìkàrẹ́ was founded by an ancestor called Àgbà-Òde who was one of the grandchildren of Odùduwà. Oyetade (2007: 2) classified Ìkàrẹ́ Àkókó as a member of the Yoruboid languages found in Akokoland i.e. the Benue Congo languages spoken in Akokoland.
Àkúrẹ́ is a city in south-western Nigeria and it is the capital of Ondo State, Nigeria. Oral tradition has it that a prince, Ọmọ́remí Ọmọlúàbí, one of the grandsons of Odùduwà left Ilé-Ifẹ̀ in search of a place to settle. When they arrived at the location where he would settle along with his entourage, the string holding the heavy royal beads on his neck snapped, thus causing the people to exclaim Àkún rẹ (the beads have snapped). This exclamation became the name of the settlement they established on the site, Akurẹ and also the dialect of Yoruba that they speak. Figure 1 below shows the genetic relationship of standard Yoruba and the two dialects.
3. Lexical Comparison
Lexical comparison is a comparative analysis with the aim of investigating the similarities and differences between two languages. Crystal (2008: 279) defines the lexicon as “the component containing all the information about the structural properties of the lexical items in a language, i.e. their specification semantically, syntactically and phonologically”. Comparative study could be carried out in the lexicon (vocabulary), phonology (pronunciation), and grammar (morphosyntax and grammar). Parkhurst & Parkhurst (2003: 1) identified two different approaches to lexical comparison each with distinct objectives; lexical similarity and historical relatedness.
Lexical similarity investigates to what extent the words of two languages are similar, often with the hopes of making a further correlation to the intelligibility between languages. For example, family and the Spanish equivalent familia are very similar to each other. If an English speaker heard the word familia, he might be able to guess the correct meaning. In most cases, the greater the lexical similarity between two variations, the more likely it is that they will be able to understand each other. Lexical similarity is only one of many factors that determine intelligibility; nevertheless it is a relatively easy place to start (Parkhurst & Parkhurst 2003).
The second approach is historical relatedness. Two words that are historically related are called cognates. While lexical similarity is most concerned with how languages appear at the present time, cognate studies are most concerned that the two varieties had the same historical root. It is possible that at one time two words may have been historically very similar, but with the natural changes that occur over time, the two words have evolved into forms that are so distinct as not to be easily recognizable. For example, the words eight and the Spanish equivalent ocho do not look or sound at all similar, yet they can both be traced to the Latin word octo (Campbell 1998). In making judgements about similarity, the assumption is that a monolingual Spanish speaker would not understand the English word. For the person studying similarity, this lack of potential intelligibility is significant. For the historical linguist, it is of little concern (Parkhurst & Parkhurst 2003).
From the two approaches to lexical comparison; lexical similarity and historical relatedness, we can say that two words can be cognates without much similarity in how they appear in the language. Similarity is relatively easy to judge while cognates are more difficult because sometimes words can appear to be cognates but really they are not. If two languages are related, there will be relatedness across linguistics disciplines such as phonology, morphology, syntax etc. Some languages can borrow lexical items from a dominant language while the rest of the language remains different from the other language.
Ayeomoni (2012) conducted a research on the lexico-syntactic exploration of Ondo and Ikale dialects of the Yoruba language. The study was a comparative study with a view to finding out the areas of convergence and divergence between the two dialects especially in the area of auxiliary verbs. It was discovered that the two dialects are closely related in the areas of lexical usage and syntactic structures. Also, they have the same lexical items in both the subject and verbal (predicate) positions and also at the adjunct position; some of the lexemes are the same in both dialects.
Castro, Flaming & Youliang (2012) described the various known dialects of Western Miao within Honghe, which include Hmong Lens, Hmong Dleub, Hmong Dlob, Hmong Bes, Hmong Soud, Hmong Ndrous, Hmong Shib, Hmong Nzhuab, Hmong Buak, Hmong Dlex Nchab and Hmong Sat. They showed that the vocabularies of the Honghe Miao dialects are extremely similar and the vast majority of words are historical cognates. They employed “lexicostatistics” method to determine the relative number of historical cognates shared by the different dialects. Pericliev (2006) carried out a computational lexical similarity analysis between five languages; Xokleng (Southeastern Brazil), Tagalog and Malay (Southeast Asia), Fijian, Samoan and Hawaiian (languages of Oceania) using 100-word lists of basic vocabulary. He found a statistically highly significant resemblance between them which he explained as being historical. He suggested the existence of genetic affinities between Brazilian Indians and Southeast Asian and Oceanic populations.
Arokoyo (2016a) conducted a study on the lexicostatistics comparison of Yorùbá, Ìgbò and Olùkùmi languages. The study carried out a comparative and lexicostatistical analysis of two varieties of Olùkùmi; Ugbodu and Ukwunzu with Yorùbá, and Ìgbò in order to discover their cognates. The essence of the study was to discover the similarities and differences and to examine the level of mutual intelligibility that exists among them. It was discovered that the two varieties examined are very different from each other. Bamigbade & Oloso (2016), while tracing the various clans of the Izon group and accessing the level of mutual intelligibility between Arogbo and Mein dialects of Ijaw language, employ lexico-semantic approach to judge the level of mutual intelligibility and ascertain the point of divergence of the dialects under study. Their findings show that 63% of the lexical items considered are similar, 21% are the same while 16% are absolutely different, hence 84% level of mutual intelligibility between the two dialects, which is an indication that both are close dialects of Ijaw. Olajide (2017) in his study observed that Obulom and Abua Languages are not dialects of the same language. However, evidence shows that they belong to the same language family. Going by the percentage of same lexical items (11%) and similar (37%) and the percentage of the lexical items that are different (52%), and considering that Swadesh’s principle indicate that languages with less that 80% cognate count should be regarded as belonging to the same language family and not dialects of the same mother language, it is convenient to conclude that Abua and Obulom belong to the same family since the cognate count is quite low.
We can deduce from the review that some of the scholars used cognate method to determine the level of relatedness and historical root in their language of study; some scholars did a comparative study, some scholars used the lexical similarity approach of comparison to investigate the extent to which words of two languages are similar with the hopes of making a further correlation to the intelligibility between languages. Furthermore, some scholars did a comparative study in the area of phonology to ascertain the phonological concepts of the language of study. Since our focus is the determination of cognate percentage in order to ascertain the level of relatedness among the dialects, it is helpful to approach the analysis using a comparative method and lexicostatistics to determine the cognate.
4. Theoretical Framework
This paper adopts two theoretical approaches; lexicostatistics and comparative method. These approaches will be examined in the following subsections.
Lexicostatistics aims at establishing linguistic relations on the basis of a quantitative comparison of vocabulary; it is the statistical study of vocabulary to discover whether languages are historically related by counting the percentage of cognates (Romaine 2000). Cognates refer to words that have the same meaning and descended from common ancestors. It is calculated by dividing the total number of items multiplied by 100 to obtain percentage cognates.
Gudschinsky (1956) identified three levels of cognate scores to determine relatedness:
-
0%–35% cognate means separate language family.
-
36%–80% cognate means separate language, same family.
-
% and above cognate means it is the same language.
Bankale (2006) identified three basic assumptions of lexicostatistics approach as follows:
-
It assumes a basic or core vocabulary which is relatively culture-free and which is less susceptible to change as other kinds of vocabulary.
-
The rate of retention of the basic vocabulary is constant through time and as such about 81 percent of the vocabulary will be retained over a millennium.
-
The rate of loss is also constant, about 14 percent will be lost over a millennium. With this in mind, the cognation count will surely give information about sub grouping of related languages.
Comparative method is a technique for studying the development of languages by performing a feature-by-feature comparison of two or more languages with common descent from a shared ancestor (Beekes 1995). This comparative method helps in filling historical gaps of a language and discovering the development of phonological, morphological and other linguistic systems between languages. It also helps in confirming or refuting perceived relationship between languages. This method was developed in the 19th century by Rasmus Rask and Karl Verner. Two languages are genetically related if they descended from the same ancestral language. For example, Italian and French come from Latin and therefore belong to the same family; Romance languages. It is of importance to note that languages have been compared since antiquity. For instance, in the 1st century BC, the Romans were aware of the similarities between Greek and Latin which was a result of Rome being a Greek colony speaking a debased dialect. According to Arokoyo (2016a), the essence of comparative method is to discover whether languages have historical connections. Similarly, this same approach was used by her to examine the phonological similarities and differences between Yorùbá, Owe, Igala and Olukumi languages (Arokoyo 2016b).
We compare languages to discover differences and similarities and to establish mutual intelligibility. Mutual Intelligibility is a major criterion in differentiating a language from a dialect. It is referred to the ability of people to understand each other. Every dialect has its linguistic origins and backgrounds which makes them either mutually intelligible or unintelligible. If two varieties of speech are mutually intelligible, they are strictly dialects of the same language; if they are mutually unintelligible, they are different languages (Hudson 2003).
According to Millar (2007: 259-260), comparative method works in the following ways:
-
We first decide by inspection that certain languages are probably genetically related and hence descended from a common ancestor.
-
We place side by side a number of words with similar meanings from the language we have decided to compare.
-
We examine these for what appear to be systematic correspondences.
-
We draw up tables of systematic correspondences we find.
-
For each correspondence we find, we posit a plausible-looking sound in the ancestral language, one which could reasonably have developed into the sounds that are found in the several daughter languages.
-
For each word surviving in the various daughters, we look at the results of (v) and thus determine what the form of that word must have been in the ancestral language.
-
Finally, we look at the results of (v) and (vi) to find out what system of sounds that the ancestral language apparently had and what the rules were for combining these sounds.
5. Data Presentation and Analysis
This section presents and analyses the data. The data to be presented and analysed were collected from native speakers of the three speech forms using the SIL Comparative African Wordlist of basic lexical items which are divided into sets such as animal nouns, edible nouns and numerals for easy comparison. The section is broadly divided into two;
The speech forms are represented as SY (Standard Yorùbá), IK (Ìkàrẹ́ Àkókó) and AK (Àkúrẹ́) respectively.
This section analyses the different sets of the lexical items based on their phonological and lexical similarities and differences. The phonological comparison; either the vowels or consonants different occurrence and observe whether it affects the meaning or not in the dialects while the lexical comparison aims to compare the lexemes of the dialects to know their areas of similarities and differences.
Animal nouns refer to living things which comprise of insects, amphibians, birds and four-legged animals. In the data in Table 1 below, we analysed 19 of them.
From the animal nouns data above, we discovered similarities in the lexical items. For instance, the word snail is [ìgbín] in SY, [ùgbԑ́n] in IK, and [ùgbín] in AK have the same tone and pronunciation with different vowels at their initial positions; the high front close unrounded vowel /i/ is at the word initial position in SY while the high back rounded vowel /u/ is at the word initial position in IK and AK showing that some of their lexical items begin with the high back rounded vowel /u/. We also see that the high front unrounded nasal vowel /ĩ/ in [ìgbín] in SY and [ùgbín] in AK is substituted with the [ùgbԑ́n] in IK. In item 11, the word maggot is [ìdũ] in SY and AK but [ìdԑ᷈] in IK having the same tone but we note that the nasal high back unrounded vowel /ũ/ in SY and AK is substituted with the nasal half-open unrounded vowel /ɛ̃/ in IK with meaning still constant. Items 13, 14, 15, and 18 are cognates too.
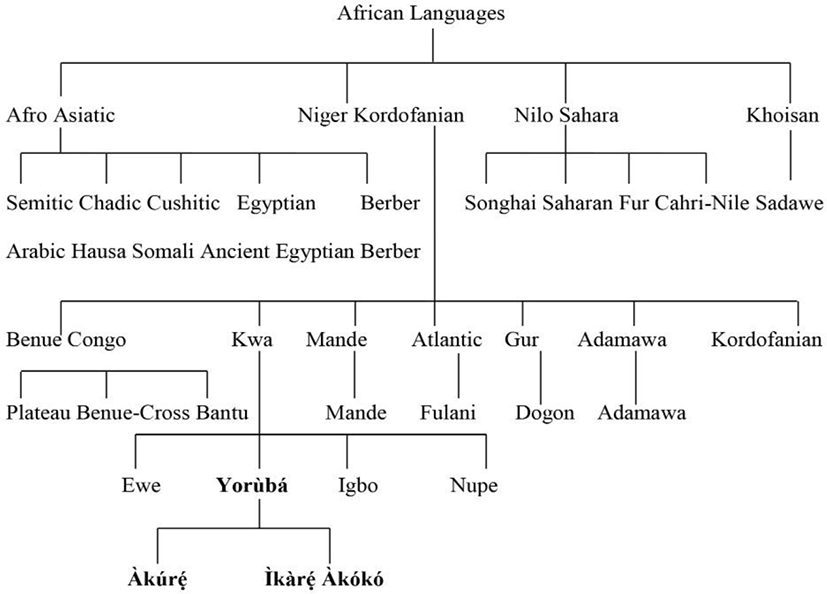
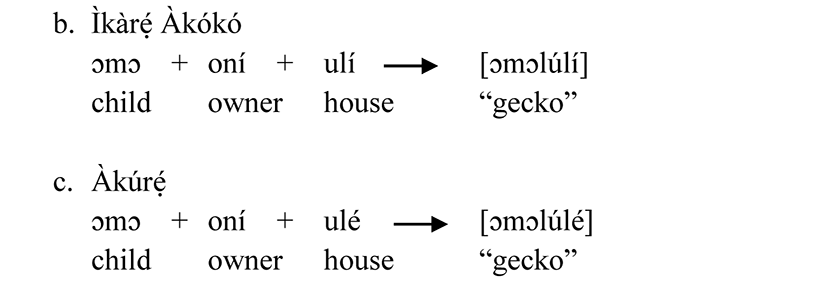
It is also observed in item 16 that there is an instance of consonant alternation; the word guinea fowl for [awó] in SY and AK but [aɣó] in IK. The voiced labia-velar approximant /w/ is substituted with the voiced velar fricative /ɣ/ in IK. There are differences in the lexical items too. For instance; in item 5; the word earthworm for [ekòló] in SY, [ikòló] in IK and [kòló] in AK, we observed that there is a case of vowel deletion at the initial position in the word [kòló] for earthworm in AK but we see vowel alternation in SY and IK; the half-close unrounded vowel /e/ in SY is substituted with the high front close unrounded vowel /i/ in IK. We can see in the data generally that there are regular sound changes either at the initial, medial or final position. In item 19, the word vulture is [igṹ] in SY and AK but [igɔ́n] in IK; we realized the differences in the vowel at the word final position in the dialects. The nasal high back unrounded vowel /ũ/ in SY and AK is substituted with nasal half-open rounded vowel /ɔ̃/ in IK. In item 2 for the word lizard, SY and IK are cognates while AK has a different one. This likely occurrence can be seen in items 8, 9 and 10 in the data above. We see an instance of different morphemes coming together give us a new word. For instance in item 4 for the word gecko, it is referred to as [ɔmɔlúlí] in IK, [ɔmɔlúlé] in AK and [ɔmɔ́lé] in SY. This can be analysed in (1) below:

Here, we observed a case of vowel deletion in SY. However, the forms are different in IK and AK as shown in (1b and 1c) below.
Edible nouns refer to something that is suitable or safe to eat. They also refer to something that can be eaten as food and consumable. There are presented in Table 2 below.
Looking at the data in Table 2 above, we see instances of vowel alternations in the lexical items. For instance; in item 1 in Table 2, the word banana for [ɔ̀gԑ̀dԑ̀] in SY and AK, and [ԑ̀gԑ̀dԑ̀] in IK; we note that the half open rounded vowel /ɔ/ in SY and AK is substituted with the half-open unrounded vowel /ԑ/ in IK. Similarly in item 4, we see that there is a case of vowel substitution at the initial position. There are cases where SY and AK share cognates while IK has a different cognate. For instance in item 5, the word yam is [iʃu] in SY and AK but [ìʤé] in IK. We also observed some differences in the lexical items i.e. lexical items from the three dialects that do not share cognates. These can be seen in item 3 and item 6. Looking at item 7 for the word food which is [ónʤԑ] in SY, [ʤԑ̀rí] in AK and [ʤíʤԑ] in AK; the morpheme ‘dʒԑ’ is constant in the dialects which means “to eat”. In item 10, high front close unrounded vowel sound /i/ in SY and AK is deleted in IK. In item 13 and item 14, we note the vowels at the initial position in the different lexical items. For instance, the word sugarcane for [èrèkè] in IK, the high front close unrounded vowel sound /i/ in SY and AK is substituted with the half-close unrounded vowel /e/ in IK. Similarly, in the word maize for [ìgbàdo] in IK, the open central unrounded vowel /a/ in SY and IK is substituted with the high front close unrounded vowel /i/ in IK.
Numeral pattern has to do with the counting system in a particular language. Every language has a counting system which is language specific. It is usually mathematical with the use of addition, subtraction or multiplication. This means that a numeral system has a particular base to which we can add to, subtract from or multiplied to generate another number (Comrie 2005). The numerals exemplified in Table 3 below are cardinal numerals from one to thirty, forty, fifty, sixty, seventy, eighty, ninety, hundred, two hundred, five hundred and one thousand.
It can be observed in the data above that the basic words for one to ten from the Àkúrẹ́ and Ìkàré Àkókó dialects are the same with the Standard Yorùbá; the difference here is that the numbers one, two, four and five in the Ìkàré Àkókó dialect is different from the Standard Yorùbá. For instance, the word two for [èʤì] in item 2, we noted a difference in the vowel at word final position; the high front close unrounded vowel sound /i/ in SY and AK is substituted with the nasal high front unrounded vowel sound /ĩ/ in IK and also applies to item 31. Similarly in item 5, where the open central unrounded vowel /a/ in SY and IK is substituted with the half-open unrounded vowel /ԑ/ in IK. The other number words in the data involve mathematical processes such as multiplication, addition and subtraction. For instance; from number 11–20 involves 1+10, 2+10, 3+10, 4+10 for eleven to fourteen which indicate addition; and 20–5, 20–4, 20–3, 20–2, 20–1 for fifteen to nineteen which indicates subtraction while twenty (ogún) is a basic word.
We also observed that Ìkàré Àkókó and Àkúrẹ́ dialects have the same counting pattern from twenty one to twenty nine which is 20+1= 21, 20+2=22, 20+8=28, 20+9=29 etc. which indicates addition of the numbering words. But in the Standard Yorùbá, from twenty one to twenty four indicates addition while twenty five to twenty nine indicates subtraction i.e. 30–5=25, 30–4=26, 30–3=27, 30–2=28 and 30–1=29. The number words; forty, sixty, eighty, hundred and thousand indicates multiplication. The formations of these words indicate coalescence; a phonological process that involves merging of two adjacent segments at the underlying level to produce a third segment at the surface level. These can be illustrated below:
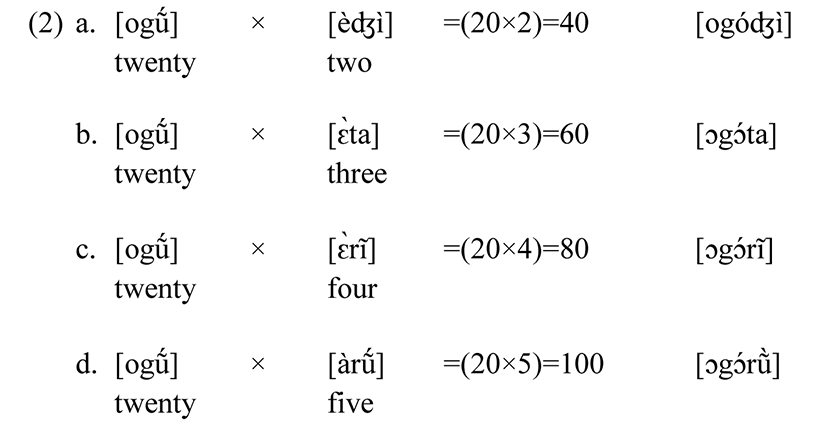
The number word; thousand indicates multiplication i.e. 200 multiplied by five which can be seen below:
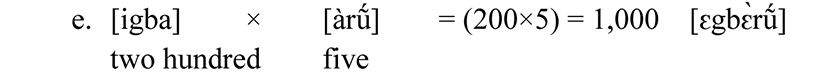
In Ìkàrẹ́ Àkókó, since the word two is [èʤĩ̀], hence forty is [ogóʤĩ̀] which indicates multiplication i.e. twenty multiplied by two. The difference between the Ìkàrẹ́ Àkókó and Standard Yorùbá and Àkúrẹ́ is that the high front close unrounded vowel sound /i/ in SY and AK is an oral vowel sound while it is a nasal vowel sound in Ìkàrẹ́ Àkókó.
Lexicostatistics comparison amongst different dialects is done by counting the number of all the lexical items and then finding the percentage of cognates from the sum of all the lexical items i.e. the number of cognates divided by the total number of all lexical items multiplied by hundred. This is indicated below:
Hence, we counted the number of all the lexical items from Standard Yorùbá, Ìkàrẹ́ Àkókó and Àkúrẹ́ in order to derive the percentage cognate. The total number of cognates counted is 1,000. Hence:
-
In order to determine the level of relatedness between Standard Yorùbá and Ìkàrẹ́ Àkókó, a total number of 789 cognates were counted and below is the lexicostatistics analysis:
-
In order to determine the level of relatedness between Ìkàrẹ́ Àkókó and Àkúrẹ́, a total number of 746 cognates were counted and below is the lexicostatistics analysis:
-
In order to determine the level of relatedness between Standard Yorùbá and Àkúrẹ́, a total number of 864 cognates were counted and below is the lexicostatistics analysis:
From our analysis, we discovered that there is a higher percentage of cognates between Standard Yorùbá and Àkúrẹ́ with 86.40%, while Ìkàrẹ́ Àkókó and Àkúrẹ́ have 74.60% cognates and Standard Yorùbá and Ìkàrẹ́ Àkókó have 78.90% cognates. We also found out that Ìkàré Àkókó and Àkúrẹ́ dialects have the same counting pattern of addition of the numbers from twenty-one to twenty-nine. In Standard Yorùbá, from twenty one to twenty four indicates addition while twenty five to twenty nine indicates subtraction and forty, sixty, eighty, hundred and thousand indicates multiplication.
The lexical items compared are similar although there are phonological variations especially vowel substitutions among the three dialects but this does not affect intelligibility. Some lexical items in Standard Yorùbá, Ìkàrẹ́ Àkókó and Àkúrẹ́ dialects are formed through a morphological process called compounding. This means that compounding is evident in the dialects.
6. Conclusion
This paper carried out a comparative study on the lexicons of Standard Yoruba, Ìkàré Àkókó and Àkúré dialects in order to determine their level of mutual intelligibility. By implication, the level of mutual intelligibility between Standard Yorùbá and Ìkàrẹ́ Àkókó is lesser even though they belong to the same language family – Yoruboid, while the level of mutual intelligibility between Standard Yorùbá and Àkúrẹ́ qualifies them as variant of the same language which the former is the standard form, the latter is the variant. The percentage cognate was done to determine the level of relatedness of the three dialects. We discovered that lexical items are similar in the varieties and we also discovered that there is intelligibility despite the various phonological variations.