




1. Introduction
Loanword adaption in Vietnamese has been a topic of interest for different scholars during the last few decades. Most of the previous works on Vietnamese lexical borrowing focused on historical, etymological, sociolinguistic, and phonological descriptions of language borrowing from Chinese, French, and English in general. Among the popular works in Vietnam, K. Nguyen (2007) provides a systematic investigation of loanwords in Vietnamese. He presents some theoretical issues related to language contact, word borrowing and gives examples of Vietnamese loanwords. He proposes three main foreign language sources i.e., Chinese, French, and English. His study is a great contribution to the field of loanwords in Vietnamese, but the discussions are limited to the sociolinguistic situation and to the descriptive phonological aspects and illustrations of loanwords from these three main source languages in various fields. G. Nguyen (1998) in “Tu Vung Hoc Tieng Viet” (Vietnamese Lexicology) also touches upon lexical borrowing in the Vietnamese language. He gives the classification of loanwords in Vietnamese language and the assimilation in terms of phonology of these foreign origin words. Tran (2009) includes loanwords from different source languages with their etymology in his dictionary.
Section1 of this paper deals with Vietnamese loan word phonology with reference to French words and its previous literature. Section 2 is devoted to Vietnamese and French phonemic inventories and phonotactic patterns. Section 3 discusses the Phonological alternations, loan words and repair strategies with special reference to French loans in Vietnamese. An OT account of French loans in Vietnamese is explained in section 4 of this paper which is divided in to two subsections 4.1 and 4.2 with detailed representation of alternations in coda and onset clusters of the loan words in constraints based approach. Section 5 summarizes the main findings and implications of the paper.
2. Vietnamese Loan Word Phonology with Reference to French Words and its Previous Literature
The eighty years of French colonial rule resulted in the enrichment of the Vietnamese language by loanwords borrowed from French. Some scholars have studied language contact between Vietnamese and French. Barker (1969) provides the first paper on French loanwords in Vietnamese, taking account of the theoretical literature in the field of research. He examines the phonemic inventory of French, the donor language and that of the host language though his discussions are limited to a general description of phoneme adjustments. Vuong (1991) investigates words originating from French in Vietnamese. Huynh (2010) provides some statistics of French loanwords used among different Vietnamese age groups in recent years. A recent paper of Kang, Pham & Storme (2014) examines French loanwords in Vietnamese with the focus on adaptation of vowels into the native language. The paper provides two case studies of French vowel integration into Vietnamese. The study supports the role of knowledge of the source language phonology that adapters bring to adaptation and provides an empirical contribution to the field of loan phonology with a detailed description of French-Vietnamese vowel adaptation. Recently, the use of English words in Vietnamese means of public communication and newspapers has attracted attention among some researchers in Vietnam. To sum up, it is clear that there is no detailed, comprehensive study on the loanword phonology of Vietnamese done in the framework of Optimality Theory (Prince & Smolensky 1993). In other words, it is obvious that most of previous studies in Vietnamese loanwords are descriptive in nature and only list the changes that the sound segments or syllables undergo. The significant studies on loanwords in Vietnamese (Barker 1969, Huynh 2010, Kang, Pham & Storme 2014) have proposed rules of deletion/epenthesis or feature change to account for their adaptation into Vietnamese. For example, inserting the vowel /i/ to break up the onset cluster /sl/ in the word /slip/ > [silip] while deleting a consonant in a coda cluster as in /gɒlf/ which becomes [ɣon]. The problem with this approach is that it does not explain why the language prefers deletion in one case but epenthesis in another case to account for French syllable initial or final consonant clusters. Likewise, a consonant can be unparsed in some contexts but be parsed in other contexts. For example, when /film/ is adapted as [fim] the segment /l/ is deleted, however, /l/ is preserved and modified as /n/ in the word /kalk/ > [kan]. Such problems mentioned above can be reasonably solved in the OT framework in terms of constraints. The surface form that arises is the outcome of the constraint interaction and satisfaction. No specific rules are needed in the OT framework since “the candidate analyses, evaluated by the constraint hierarchy, are admitted by very general considerations of structural well-formedness” (McCarthy & Prince 1993: 5). No derivational steps are involved as the computation of the candidate set happens in parallel. Moreover, the OT framework mainly focuses on the surface or output form. Whatever be the underlying representation of the foreign loanwords (in French), they ultimately have to conform to the surface constraints of the recipient language (i.e., Vietnamese). The foreign forms will come out looking like the surface forms of the recipient language (Vietnamese). By inspecting the surface forms, the constraints and their ranking in a particular language can be worked out.
This paper aims to shed light on the loanword adaptation phenomenon, with special reference to French loans in Vietnamese, which will be a contribution to an understanding of the internalized phonology of the Vietnamese language. The research endeavors to provide a basis of description of the language for any further research. The scope of the study is limited to the source language, French and the Vietnamese we examine is standard Vietnamese, i.e., the Hanoi dialect. The following research questions will guide our study: Firstly, how are foreign consonant phonemes adapted into Vietnamese? Secondly, how do Vietnamese speakers nativize foreign syllable structures that are incompatible with their native phonology?
For the purpose of the present study, the main source of data is from print materials such as the paper by Barker (1969), the list of French loanwords in the thesis of Huynh (2010), the book on loanwords of K. Nguyen (2007), dictionary of loanwords in Modern Vietnamese by Tran (2007), French-Vietnamese dictionary and Vietnamese-French dictionary. The selected list of words was checked in pronunciation by some Vietnamese who are speaking Hanoi dialect. They are mostly lexical items introduced into Vietnamese after the French came to Vietnam. Lexique 3.80 (New et al. 2001), which is available at <http://www.lexique.org> is used as a source of French phonological transcription. The phonological transcription of the Vietnamese French loans is provided by Kirby with the aid of vPhon, a Python script that converts Vietnamese scripts to IPA transcriptions (Kirby 2008) and from the SEAlang Library Vietnamese Lexicography, which is available at <http://sealang.net>.
3. Vietnamese and French Phonemic Inventories and Phonotactic Patterns
In this section we are going to focus on the Vietnamese and French phonemic inventories and phonotactic rules governing onset and coda formations now.
In Vietnamese, consonant phonemes may precede or follow a vowel nucleus or syllabic sound to form a word. Standard Vietnamese has a total number of consider 19 initial consonants. There is one phoneme /p/, which is the counterpart of /ɓ/ that only occurs in the initial position in some loanwords; e.g., pin /pin/ ‘battery’ and pan /pan/ ‘breakdown’. The inventory of Vietnamese initial consonants is given in Table 1 below.
| Labial | Labio-dental | Dental | Alveolar | Palatal | Velar | Glottal | |
|---|---|---|---|---|---|---|---|
| Plosive | ɓ (p) | t th | ɗ | tɕ | k | ʔ | |
| Nasal | m | n | ɲ | ŋ | |||
| Fricative | f v | s z | x ɣ | h | |||
| Approximant | w | l |
Vietnamese only allows voiceless stops /p, t, k/, nasals /m, n, ŋ/, and two glides /w, j/ in coda position. Certain final consonants are allophones of these sounds. The following table shows that the palatals and the plain and labialized dorsals are allophones of the same phoneme, i.e., [c], [k], and [k͡ p] are allophones of [k], while [ɲ], [ŋ] and the [ŋ͡ m] are allophones of [ŋ].
After back rounded vowels such as /u, o, ɔ/, the codas /k, ŋ/ are produced as doubly articulated labial-velars. The consonantal phonemes inventory given in Table 2 below reveals that French lacks the glottal fricative /h/ although it has the orthographic letter /h/ in written form. For example, the word ‘hectare’ is pronounced as /ɛktaʁ/ instead of */hɛktaʁ/ and this orthography of the donor language will be relevant to the adaption of French loans in Vietnamese.
| Consonants | p | t | c | k | k͡p |
|---|---|---|---|---|---|
| m | n | ɲ | ŋ | ŋ͡m | |
| Glides | w | j |
The donor language allows a rich inventory of consonantal codas and consonantal clusters while Vietnamese has a restriction on which consonants occur in codas. The nasals /m, n, ɲ, ŋ/, voiceless stops /p, t, k, c/ and glides /w, j/ are allowed in coda position in Vietnamese. In addition, consonant clusters do not occur in both onset and coda positions.
Hence, when French consonants are adapted into Vietnamese, consonants and consonant clusters undergo the process of phonologization so that the loanwords can conform to Vietnamese phonotactics. This brief comparison between French and Vietnamese clearly establishes the fact that those loanwords in Vietnamese invariably undergo both phonological changes at the segmental and syllabic levels.
| Labial | Dental | Alveolar | Post-alveolar | Palatal | Labial-palatal | Velar | Uvular | |
|---|---|---|---|---|---|---|---|---|
| Plosive | p b | t d | k g | |||||
| Nasal | m | n | ɲ | ŋ | ||||
| Fricative | f v | s z | ʃʒ | ʁ | ||||
| Approximant | w | l | j | ɥ |
4. Phonological Alternations, Loan Words, and Repair Strategies with Special Reference to French Loans in Vietnamese
In this section, we will concentrate on the phonological repair strategies the Vietnamese phonology adapts while borrowing the French consonant clusters at the syllabic level. In other words, we are going to highlight the phonotactic adjustments that the recipient language (Vietnamese) undergoes to conform to its syllable structure rules. For instance, the CC clusters of French may undergo either vowel epenthesis or deletion when entering Vietnamese. These two repair strategies are discussed below:
In the Vietnamese loanword phonology, epenthesis is the addition of a vowel inside the consonant cluster. It happens when the borrowed words from French have consonant clusters, which native Vietnamese does not allow. Epenthesis seems to be the preferred strategy to repair the onset clusters in many languages such as Burmese (Chang 2009), Shona (Uffman 2006) and others. The treatment of foreign onset clusters is summarized in Table 4. The data in this table shows that a few clusters adopt either epenthesis or deletion (e.g., /st/, /bl/, /gl/) and most clusters are repaired by deletion.
| French clusters | bʁ | fʁ | tʁ | gʁ | kʁ | bj | sf | st | sk | sp | bl | gl | kl | pl | sl |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Adaptation bymetathesis | |||||||||||||||
| Adaptation byepenthesis | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||||||
| Adaptation bydeletion | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ||||
| Non-adaptations |
Table 4 shows that French onset clusters either opt for epenthesis or deletion while they enter into the domain of Vietnamese syllabic patterns.
Examples of vowel epenthesis are given in Table 5. For instance, the onset cluster /bl/ in /bluz/(‘overall’) or in /klɔʁ/(‘chlorine’) is adapted by vowel insertion and resyllabified as an onset in the Vietnamese forms, are respectively /bɤlu/ and /ɣɤluko/.
Another strategy to avoid the clusters is deletion. The deletion can be the first segment (C1) or the second segment (C2) of the cluster. In some cases, one consonant changes its features and the other one is deleted (where both C1 and C2 are illicit segments). In the literature of loan phonology, consonant deletion is also the most frequent strategy applied to adapt the foreign consonant clusters in coda position. For instance, this process is applicable in Fijian loanword adaptation (Kenstowicz 2003). The summary of coda cluster treatment is shown in Table 6.
| French clusters | st | ʁk | ʁd | tʁ | dʁ | ps | ks | bʁ | ʁʃ | ʁs | bl | ʁl | lv | lf |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Adaptation bymetathesis | ||||||||||||||
| Adaptation byepenthesis | ||||||||||||||
| Adaptation bydeletion | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Non-adaptations |
Table 6 shows that only deletion occurs as a repair strategy for coda clusters in Vietnamese. In the following tables, we present examples of deletion for both onset and coda clusters.
| Clusters | French | Vietnamese | Gloss |
|---|---|---|---|
| /st/ | /faʃist/ | /fatsit/ | ‘fascist’ |
| /ʁk/ | /maʁk/ | /mak/ | ‘mark’ |
| /ʁd/ | /kɔʀd/ | /kɔt/ | ‘rope’ |
From the above presentation, it can be concluded that the consonant deletion seems to be more preferred strategy in Vietnamese loanword adaptation to repair both onset and coda clusters, as the examples of deletion outnumber the examples of epenthesis in the data set under consideration.
5. An OT Account of French Loans in Vietnamese Phonology
In this section, we are going to look at the coda and onset clusters of French loans in Vietnamese within the OT model of constraint rankings although our analysis is confined to the repair strategies that Vietnamese loan phonology exhibits at the syllabic level. The prime focus of our interpretation in our study is the nativization of foreign consonant structures which are not allowed in the native language. So far this issue has not been perceived from the perspective of OT which can explain universal typology across languages in the world on an explicit canvas with suitable rational justification. By using the constraint based approach within OT we will show here how a uniform set of constraints can account for phonological adaptation at the syllabic and segmental level. Loan word adaptation and constraint based approach also bear close affinity with strength asymmetries evident in the patterning of segmental speech sounds not only in a specific language but also in languages across the world. Dutta (2012) claims that phonological strength relations can play a crucial role in the patterning of phonological features not only in the areas pertaining to language acquisition, pitch accent patterns and tonal phenomenon but also to loan word adaptation. The constraint ranking approach in OT can better represent this phenomenon in a comprehensive and clear fashion.
Here we have noticed that the French loanwords strictly conform to the Vietnamese syllable structure patterns which imply that the markedness constraints of Vietnamese are higher ranked and they act as a sieve through which the French loanwords pass.
To explain the native syllable inventory of Vietnamese, we can use the blanket constraint OK-, introduced by Yip (1993). She introduced this constraint as a package constraint to deal with four different constraints at the level of the syllable in Cantonese. The first one is a constraint that deals with onsets. It is a combination of a constraint that blocks onset deletion (the Onset Principle formulated by Itô 1989) and another that avoids consonant clusters in the onset position i.e., * [CC. The second constraint of the package that she mentions is NUCLEUS, which means nuclei must always be vocalic. Word-finally, however, in Cantonese, nuclei may be any [+son]. The third one is a constraint which restricts the set of possible codas to /p, t, k, m, n, ŋ, w, j/. The fourth constraint is MINSYLL, which means the minimal syllable in Cantonese is bimoraic i.e., [µµ]MINσ. Likewise, for Vietnamese, we propose the OK- constraint that is also a package of constraints related to do with syllable structure. (i) Firstly, Vietnamese does not allow either a complex onset or a complex coda. (ii) Secondly, the nucleus is always vocalic, as Vietnamese does not allow syllabic consonants. (iii) Thirdly, Vietnamese restricts the set of possible codas (like Cantonese) to /p, t, k, m, n, ŋ, w, j/ only. In addition to this, Vietnamese also has restrictions on what can occur in the onset position. Regarding onset segments, Vietnamese only allows loanwords with sounds which are present in the native language (except /p/, which is accepted in some French loanwords). This means that the French segments like /g/, /ʁ/, /ʃ/, /ʒ/, /j/, and /ɥ/ are not allowed in loanwords in onset position. However, the constraint MINSYLL in the package constraint of OK- in Yip (1993) is not observed in Vietnamese as it can have mono-moraic words like [ba] ‘three’, [ve] ‘to return’, or [mɛ] ‘mother’, i.e., CV syllables.
Postulating the ‘OK-’ constraint implies that Vietnamese has to introduce some repair mechanisms to accommodate French words that violate any of these constraints. Onset and coda clusters are not allowed by the phonotactic rules of Vietnamese phonology. Particularly, syllabic consonants can’t find a place in Vietnamese and certain disallowed segments in Vietnamese are either deleted or altered.
The next important feature that we have observed here in this data set is that a particular segment is subject to deletion in either an onset cluster or a coda cluster of the French loanwords and thereby it conforms to the phonotactic patterns governing syllabification of the native Vietnamese. The tables displaying the changes are listed below for the convenience of the readers:
The onset clusters represented in Table 9 and Table 10 below aptly illustrate the process of phonologization and repair strategy. Here the two repair strategies that Vietnamese phonology adopts in case of French loans are either epenthesis or deletion.
In a complex onset as shown in Table 10 if we have a consonant that is licit and another that is illicit (i.e., the segment is not permitted in Vietnamese), the licit consonant survives (e.g., /kʁavat/ > /kavat/ or /kɔ̃.plɛ/ > /kɔm.le/ (as /ʁ/ and /p/ are not allowed in onset position).
This is because of the high ranked constraint OK-. However, when we have consonant clusters (an obstruent + a sonorant) that are both allowed in Vietnamese, we find either epenthesis or deletion of the obstruent to repair the syllable. For instance, for cluster /bl/, which has two segments that are both allowed in Vietnamese, we find either deletion of the obstruent or epenthesis (e.g., /blɔk/ > /lok/ or /bɤlok/).
| French | Vietnamese | Gloss |
|---|---|---|
| /elips/ | /elip/ | ‘ellipse’ |
| /vɛst/ | /vɛt/ | ‘jacket’ |
| /litʁ/ | /lit/ | ‘litre’ |
In this case, the consonant that is not permitted by Vietnamese phonology is deleted and the other is retained.
| French | Vietnamese | Gloss |
|---|---|---|
| /fuʁʃ/ | /fuək/ | ‘pitchfork of bike’ |
| /kɔʁd/ | /kɔt/ | ‘spring’ |
In this case, it is always the second consonant that survives and is modified according to Vietnamese phonology.
| French | Vietnamese | Gloss |
|---|---|---|
| /valv/ | /van/ | ‘valve’ |
| /ɡɒlf/ | /ɣon/ | ‘golf’ |
In this case, it is the sonorant that is retained (and modified) and the obstruent is deleted.
| French | Vietnamese | Gloss |
|---|---|---|
| /kabl/ | /kap/ | ‘cable’ |
| /pɛʁl/ | /bɛk/ | ‘bead’ |
These are words with consonant clusters in the coda which violate the Sonority Sequencing Principle. In these cases, the obstruent remains and the sonorant is deleted.
Based on the above observation, it can be seen that the foreign coda clusters are repaired by deletion to bring the form into conformity with the Vietnamese phonotactic patterns. However, there is one case where the coda cluster is adapted by adding a vowel, as seen in Table 15.
| French | Vietnamese | Gloss |
|---|---|---|
| /kalk/ | /kankɛ/ | ‘to trace’ |
This is a Sonorant (illicit) + Obstruent (licit) cluster and both the sonorant and the obstruent are retained and the complex coda is repaired by epenthesis. To account for these complex facts, we need to introduce some constraints in OT framework and this process is discussed in the following subsection.
5.1. Alternations in Coda Clusters and Constraint Based Approach in OT
In the first list of obstruent + obstruent coda clusters, we find that the segment that is allowed according to Vietnamese phonology remains and the other is deleted (the third constraint of the OK- constraint). When one of them is licit and the other is illicit (e.g., calque), we observe retention of both segments. The illicit segment /l/ is modified to /n/ and the /k/ is retained. The complex coda is avoided by epenthesizing a vowel at the end of the word.
When both the segments are illicit in the coda position and when both are obstruents, it is the first that deletes and the second consonant undergoes phonological changes. What interests us is the list of sonorant + obstruent clusters, where both are disallowed. In this case, it is the sonorant that survives (the /l/ is changed to /n/) when it precedes the obstruent. In cases, of the reverse order, where there is a violation of the Sonority Sequencing Principle (SSP), it is the obstruent that survives.
We introduce two new constraints to account for these facts; namely, PARSE-SALIENT/ MIMIC-SALIENT and ALIGN-R.
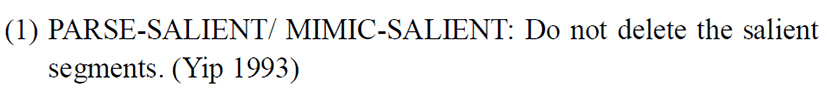
In Vietnamese, we believe the threshold of saliency, is based on the Sonority Sequencing Principle developed by Clements (1990), Dost (2004), and others. The sonority scale shows that the obstruents are the least sonorous elements, nasals are more sonorous than obstruents, liquids are more sonorous than nasals but less than glides and vowels are the most sonorous elements.
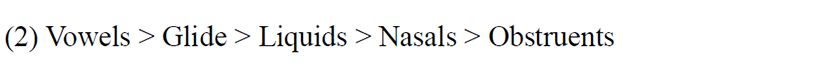
From the data, it is clear that obstruent sounds can freely delete in Vietnamese while all other sounds (namely, sonorants) are above the salient threshold and have to be parsed. Jacobs & Gussenhoven (2000) objected to the use of salience as a feature in accounting for the application or non-application of a rule as the notion of salience is language specific and not a universal feature. Hence, to avoid using the notion of salience (which is language specific), we could instead rename the constraint PARSE SALIENCE as a more general constraint MAX-SON. The sonorant survives because of the constraint, namely MAX-SON.

In the coda position, we note that deletion is a more favorable strategy than epenthesis (epenthesis only happens to the word “calque”). When we have two illicit segments in the coda position, it is the first member of the cluster that is deleted.
This shows us that we need the constraint ALIGN-R, which is a high ranked one in Vietnamese.
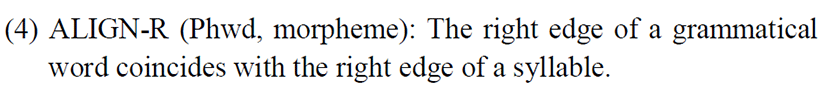
In order to keep the feature in the output similar to the input, we also require the constraint IDENT-F shown in (5).
In addition, we note that two more faithfulness constraints, which are active in Vietnamese loanword phonology, are DEP-IO and MAX-IO.


The set of constraints analyzed earlier are presented once again below for the convenience of the readers from (8) to (11):
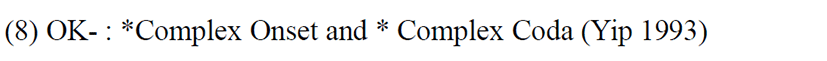
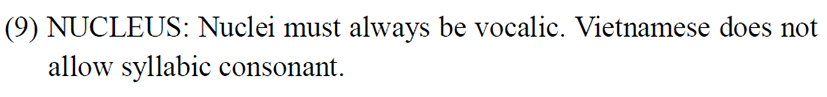
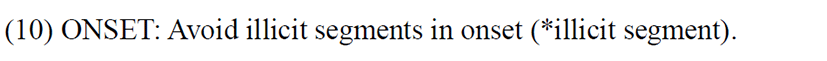
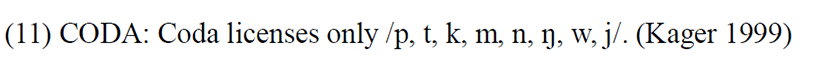
Now we are going to show the OT constraint rankings exhibited by the coda clusters in Vietnamese. The OT tableaus can better illustrate the ordering of these constraints which can display the patterns of obstruent + obstruent coda cluster (one licit and another illicit) in Vietnamese loan phonology.
The first process is one in which C1 is a licit obstruent and C2 is an illicit obstruent. The licit C1 remains as coda of the original syllable and the illicit C2 undergoes deletion. For this case, we consider the word /elips/, which becomes [elip]. To account for this phonological change, we require the above constraints. The ordering of the constraints is summarized in (12).
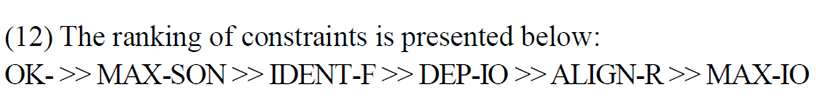
The tableau in Table 16 illustrates the explanation of the adaptation of the word /elips/, which changes to /elip/.
| /elips/ | OK-σ | MAX-SON | IDENT-F | DEP-IO | ALIGN-R | MAX-IO |
|---|---|---|---|---|---|---|
| a. /elips/ | *! | |||||
| b.☞/e.lip/ | * | * | ||||
| c. /e.lis/ | *! | * | ||||
| d. /e.lip.si/ | *! | * |
In /elips/ > /elip/, the ranking of DEP-IO >> ALIGN-R >> MAX-IO leads to the choice of candidate (b), in which only the segment /s/ in the coda cluster is deleted. Candidate (c) violates the highest constraint OK-, in particular, the coda licenses only /p, t, k, m, n, ŋ, w, j/ and candidate (a) also fails due to its violation of the highest constraint OK-, in particular, *Complex-Coda.
To simplify the obstruent + obstruent cluster with both illicit segments, we found that C1 is deleted and C2 is modified. This take place, for instance, in the adaptation of /kɔʁd/ > /kɔt/, where the first member of the cluster /ʁd/ is deleted and the second one is modified. In this case, we also require the same constraints such as OK-, MAX-SON, DEP-IO, IDENT-F, ALIGN-R, and MAX-IO. As shown in Table 17 below, the highest constraint OK- rules out most of the candidates, which are candidates (a), (b), (c), and (f). Particularly, candidate (a) is ruled out due to the fatal violation of OK- (i.e., *Complex Coda). Both Candidates (b) and (c) also violate the OK- (i.e., Coda License). Thus, candidate (d), on violating only one feature (voice) becomes the optimal one meanwhile candidate (e), violating two features (voice and place) is banned. This shows us that IDENT-F is a gradient constraint.
| /kɔʁd/ | OK-σ | MAX-SON | IDENT-F | DEP-IO | ALIGN-R | MAX-IO |
|---|---|---|---|---|---|---|
| a. /kɔʁd/ | *! | |||||
| b. /kɔʁ/ | *! | * | * | |||
| c. / kɔd/ | *! | * | ||||
| d.☞/kɔt/ | * | * | ||||
| e. /kɔp/ | **! | * | ||||
| f. /kɔʁ.de/ | *! | * | * |
To explain the adaptation of sonorant + obstruent coda clusters, we consider the foreign word, /valv/, which becomes /van/ in Vietnamese. There is no vowel insertion betweenor after /lv/. The obstruent is deleted and the sonorant is changed to /n/, which has got the closer correspondence with the input segment. So, we will be using the constraints like OK-, MAX-SON, DEP-IO, IDENT-F, ALIGN-R, and MAX-IO to account for the phonological alterations. The adaptation of /valv/ > /van/ will be the explained by OT tableau in Table 18. As shown in Table 18 below, only candidates (d) and (e) obey the highest ranked constraint OK-σ. However, Candidate (e) is not allowed as it violates a high ranked constraint IDENT-F twice (it has two different features i.e., place and manner). Therefore, candidate (d) wins and becomes the optimal candidate as it violates only one feature (place).
| /valv/ | OK-σ | MAX- SON | IDENT- F | DEP-IO | ALIGN- R | MAX- IO |
|---|---|---|---|---|---|---|
| a. /valv/ | **! | |||||
| b. /val/ | *! | * | * | |||
| c. /vav/ | *! | * | * | |||
| d.☞/van/ | * | * | * | |||
| e./vam/ | **! | * | * | |||
| f. /val.ve/ | *! | * | * |
To consider the words with illicit obstruent and sonorant segments in coda position, we take the example of the word /kabl/ which changes to /kap/. As mentioned earlier, the input consonant cluster violates the Sonority Sequencing Principle. Let us see if the constraints that we have posited so far can account for the output /kap/. As shown in Table 19, if we have only the constraints mentioned above, the optimal candidate could hypothetically be a form like /kan/ instead of the attested form /kap/.
| /kabl/ | OK-σ | MAX-SON | IDENT-F | DEP-IO | ALIGN-R | MAX-IO |
|---|---|---|---|---|---|---|
| a. /kabl/ | *! | |||||
| b. /kab/ | *! | * | * | * | ||
| c. /kal/ | *! | * | ||||
| d. /kap/ | *! | * | * | * | ||
| e.☞*/kan/ | * | * |
In recent years, a great deal of attention has been devoted to the implementation of Mora Theory in an Optimality-theoretic framework (e.g., Sherer 1994, Zec 1995, Sprouse 1996, Broselow et al. 1997). When we look at the data given above, we note that the syllabic consonant /l/ which is the nucleus of the second syllable (and which would thus be assigned a mora) is not permitted to become the coda (or margin of a syllable in Vietnamese, in which case, it would lose its mora as coda consonants do not add to the weight of a syllable in Vietnamese.) There is a tension in the language between retaining the mora (as it is in the input) and obeying the constraints of Vietnamese.
It is resolved by deleting the segment itself. Hence, to account for this fact, we need to take recourse to another constraint i.e., IDENT-IO (µ) as shown in (13) below.
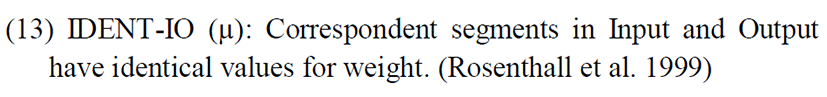
Let us see how we can now account for the facts. Let us assume that the liquid /l/, being a syllabic consonant in French, comes with a mora in the input. The explanation for /kabl/ > /kap/ is presented in Table 20 below.
| /kablµ/ | OK-σ | IDENT-IO (µ) | MAX-SON | IDENT-F | DEP-IO | ALIGN-R | MAX-IO |
|---|---|---|---|---|---|---|---|
| a. /kablµ / | **! | ||||||
| b. /kab/ | *! | * | * | * | |||
| c. /kal/ | *! | * | * | ||||
| d.☞/kap/ | * | * | * | * | |||
| e. /kan/ | *! | * | * | ||||
| f. /kaplv/ | *! | * | * | * |
If we consider the tableau in Table 20, candidate (a) violates OK- (as /b/ is not permitted in the coda of a syllable and as syllabic consonants are not allowed). Candidates (b) and (c) violate the same constraint as the segments /b/ and /l/ are not allowed as coda in the native language. In (e), the segment /b/ has been deleted and the syllabic consonant /l/ becomes the coda of the previous syllable, changing to /n/ but losing its mora. Though /n/ is allowed in the coda position, in this case, there is violation of the constraint IDENT IO (µ) as a segment that had a mora in the input loses it in the output. Candidate (f) also violates the same constraint, as /l/ has now become the onset, thereby losing its mora again. Hence, candidate (d) is the optimal candidate. In this case, we have deletion of the segment /l/ itself, which would be a violation of MAX-SON as well as MAX-MORA (part of the MAX family) and not an IDENT-MORA violation.
Regarding the sonorant and obstruent cluster, we find only one case in our data that is, /kalk/ that becomes /kankɛ/. We attribute this to the constraint ALIGN-R, which disallows epenthesis at the right edge. In this case, the sonorant /l/ changes to /n/ and the obstruent is preserved. The constraints posited so far will not give us the right result as seen below:
From the tableau shown in Table 21, we can see that candidate (a) which has a complex coda, violating the highest constraint OK-, is banned in the native language. Both candidates (b) and (d) consist of the coda /l/, which also violates OK- (i.e., Coda licensing). Candidate (c), which deletes the sonorant /l/, violates another high ranked constraint MAX-SON. Candidate (e) violates IDENT-F as /l/ changes to /n/, DEP-IO because of epenthesis of the vowel and ALIGN-R. Hence, candidate (f) will be the optimal candidate. However, this is not the right result!
| /kalk/ | OK-σ | MAX-SON | IDENT-F | DEP-IO | ALIGN-R | MAX-IO |
|---|---|---|---|---|---|---|
| a. /kalk/ | *! | |||||
| b. /kal/ | *! | * | * | |||
| c. /kak/ | * | * | ||||
| d. /kal.ke/ | *! | * | ||||
| e. /kan.kɛ/ | * | * | * | |||
| f.☞/kan/ | * | * | * |
How is this word different from /valv/, which also has a sonorant followed by an obstruent? The only difference between a word like /kalk/, which becomes /kanke/ in Vietnamese and a word like /valv/ that becomes /van/ is the fact that in the former case, the obstruent /k/ is a licensed segment in Vietnamese as /k/ is a possible coda in Vietnamese (unlike the obstruent /v/ in /valv/ which is not permitted in coda position). In the word /valv/, we noted that the obstruent is lost and the sonorant is retained. In the case of /kalk/, however, both the sonorant and the licensed obstruent are retained. This is accomplished in the language by means of epenthesis of a vowel at the end. We noted that the ranking of constraints given for /valv/ would not give us the right results for /kalk/. Hence, we need to introduce a new constraint MAX-LICENSED SEGMENT.
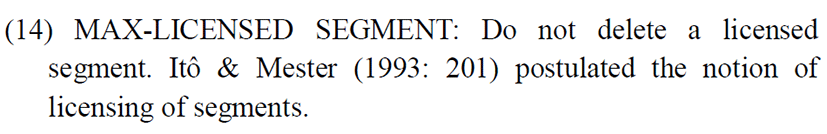

The segment /k/ is a licit segment in the coda position. It thus constitutes a licensed segment. If the constraint MAX-LICENSED SEGMENT is higher ranked than IDENT-F, we obtain the right results. Table 22 shows below the derivation of of /kalk/ > /kankɛ/.
| /kalk/ | OK-σ | MAX-SON | MAX-LICENSED SEGMENT | IDENT-F | DEP-IO | ALIGN-R | MAX-IO |
|---|---|---|---|---|---|---|---|
| a. /kalk/ | *! | ||||||
| b. /kal/ | *! | * | * | * | |||
| c. /kak/ | *! | * | |||||
| d. /kal.ke/ | *! | * | |||||
| e.☞/kan.kɛ/ | * | * | * | ||||
| f./kan/ | *! | * | * | * |
Having looked at the repair strategies used to accommodate coda clusters in Vietnamese, we now examine onset clusters in the following sub section.
The changes perceived in the onset position in Vietnamese loanwords are different from what we have observed in the coda position. In onset clusters, we find that Vietnamese adapters undergo both epenthesis and deletion to avoid the clusters.
In order to provide an explanation for phonological changes to onset clusters, we require the constraints which have been used earlier. In addition to these constraints, we need to postulate another constraint ALIGN-L.
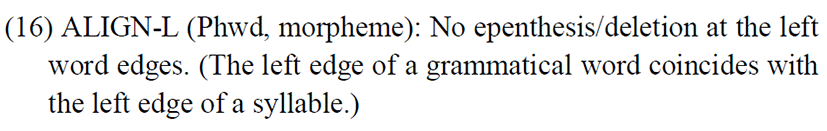
To illustrate a case when one segment C1 is licit and another (C2) is illicit, we take the example word, /kʁavat/, which becomes /kavat/ in Vietnamese. The illicit sound segment /ʁ/ gets deleted and /k/ remains. To account for this change, we need the constraints like OK-, which will be higher ranked constraint. Other constraints such as MAX-SON, IDENT-F, ALIGN-L, DEP-IO, and MAX-IO are required. (The constraint ALIGN-R is not mentioned here, as it is irrelevant). The tableau to explain for the adaptation of /kʁavat/ > /kavat/ is shown in Table 23 below.
| /kʁavat/ | OK-σ | MAX-SON | MAX-LICENSED SEGMENT | IDENT-F | DEP-IO | ALIGN-L | MAX-IO |
|---|---|---|---|---|---|---|---|
| a. /kʁa.vat/ | *! | ||||||
| b.☞/ka.vat/ | * | ||||||
| c. /ki.ʁa.vat/ | *! | * | |||||
| d. /ʁa.vat/ | *! | * | * | ||||
| e. /ik.ʁa.vat/ | *! | * | * |
We can see that OK-σ, the highest ranked constraint bans candidates (a), (c), (d), and (e) as they violate the third constraint of the blanket constraint OK-, which deals with disallowed consonants in the onset of the native language. The Candidate (b) violates the lowest ranked constraint, MAX-IO and it becomes optimal.
Now let us discuss the French word /slip/, which changes to /silip/. Here, we observe that the two segments are both in the native language; the vowel /i/ is inserted between the onset clusters to repair the foreign syllable. No new constraint is required for this repair. The illustrative of OT tableau is given in Table 24 below.
| /slip/ | OK-σ | MAX-SON | MAX-LICENSED SEGMENT | IDENT-F | DEP-IO | ALIGN-R | MAX-IO |
|---|---|---|---|---|---|---|---|
| a. /slip/ | *! | ||||||
| b. /lip/ | *! | * | * | ||||
| c. /sip/ | *! | * | * | ||||
| d. ☞/silip/ | * | ||||||
| e. /is.lip/ | *! | * | * |
From Table 24, we see that OK-σ bans candidates (a) and (e) which are not allowed in Vietnamese (as a result of *Complex Coda and illicit coda, respectively). Both candidates (b) and (c) violate two other high ranked constraints, MAX-SON and MAX-LICENSED SEGMENT. Therefore, candidate (d) wins and becomes the optimal candidate.
We noted earlier, that in some cases, we find there is optionality in the pronunciation of words like /blɔk/ or /blø/. In such words, the onset cluster /bl/ in these words may be repaired by either deletion of the obstruent or vowel epenthesis in between the cluster. To account for this, we need to posit the two constraints, ALIGN-Land DEP-IO as floating constraints. The Floating Constraint Approach was developed by Reynolds (1994) (cf. Cardoso 2009: 183). In the “floating constraints” approach, the grammar is defined by a single constraint hierarchy, in which one or more constraints may float with respect to another constraint or set of constraints.
Let us take the word /blɔk/, which changes to /bɤlok/. We can see that the onset cluster /bl/ is broken by the vowel /ɤ/ in between the cluster. There is another possibility, where /blɔk/ changes to /lok/: the cluster /bl/ is reduced to /l/, because /b/ is deleted. This optionality in the pronunciation of /blɔk/ indicates that the two constraints Align-Land Dep-IO are floating constraints. The floating constraints also explain for the words like /blø/ and /bluzɔ̃/, where the cluster /bl/ can be repaired by either epenthesis or deletion.
With regard to the case where both sound segments are preserved, the ranking will be as shown below:

This ranking shows that ALIGN-L is higher ranked than DEP-IO. This means that the epenthesis is attested. The explanation for the adaptation of /blɔk/ > /bɤlok/ is shown in OT tableau in Table 25 below.
| /blɔk/ | OK-σ | MAX-SON | IDENT-F | DEP-IO | ALIGN-L | MAX-IO |
|---|---|---|---|---|---|---|
| a. /blɔk/ | *! | |||||
| b. /lok/ | *! | * | ||||
| c. /bok/ | *! | * | * | |||
| d.☞/bɤlok/ | * | |||||
| e. /ɤblok/ | *! | * | * |
The tableau 25 shows that candidate (a) violates the highest ranked package constraint OK- (i.e., *Complex Onset). The Candidate (c) is banned because it violates another high ranked constraint, MAX-SON, which is against the deletion of sonorants. Candidate (b) violates ALIGN-L where the segment of the left side of the word edge is deleted and it violates MAX-IO. The last candidate violates three constraints in which OK- is the highest ranked constraint so it is also ruled out. Thus, the candidate (d) becomes the optimal one as it violates the lower ranked constraint.
For the pronunciation with the deletion of the obstruent, we need to re-rank the two adjacent constraints DEP-IO and ALIGN-L and the new ranking is shown in (18).

The ranking of DEP-IO >> ALIGN-L triggers the deletion of C1 in the pronunciation of /blɔk/ > /lok/. The candidate (b) /lok/ becomes the optimal output as it violates the lower ranked constraint, ALIGN-L, while candidate (d), /bɤlok/ loses due to its violation of the higher ranking DEP-IO. The remaining candidates are ruled out by the highest ranked constraint, OK- and by higher ranked MAX-SON.
| /blɔk/ | OK-σ | MAX-SON | IDENT-F | DEP-IO | ALIGN-L | MAX-IO |
|---|---|---|---|---|---|---|
| a./blɔk/ | *! | |||||
| b.☞/lok/ | * | * | ||||
| c. /bok/ | *! | * | * | |||
| d. /bɤlok/ | *! | |||||
| e. /ɤb.lok/ | *! | * | * |
To sum up, in this section we examined the phonotactic processes in Vietnamese adaptation of foreign CC clusters. Generally, consonant deletion occurs more frequently than vowel epenthesis. In addition, this section shows that vowel epenthesis (preservation) correlates with licit segments allowed in the native language.
6. Conclusion
The adaptation of foreign phonemes supports the role of the native language. The patterns of the process of phonologization are not random but quite systematic. In French loans adapted in Vietnamese, foreign segments which are not present in the native language, are completely banned. Phonotactic adaptations of illicit syllable structures showed that deletion is the favored option to avoid clusters in the coda position. Onset clusters, which are disallowed in native Vietnamese, are repaired either by the strategy of epenthesis or deletion. Hence we have postulated the constraint hierarchy for the Vietnamese loan phonology in this schemata: OK-σ >> IDENT-IO (µ) >> MAX-SON >> MAX-Licensed segment >> IDENT-F >> ALIGN-L/ ALIGN-R >> DEP-IO >> MAX-IO. This study has some practical implications for Vietnamese phonology and loanword phonology in general. The findings of the study reveal that the constraints needed and their rankings play an important role in loanword adaptation. As loan word adaptation is in a state of flux we find certain constraints that are floating, which leads to optionality in pronunciation. This study has more critical perspective on Vietnamese loan word phonology with more detailed and scientific phonological explanations in OT framework, in contrast to previous research on loan adaptation in Vietnamese (Barker 1969, Huynh 2010, K. Nguyen 2007) which gave descriptions in relation to general phonology and etymology.