1. Introduction
We speak of colexification (cf. e.g., François 2008) when two distinct word meanings are expressed in one language by a single lexeme (i.e., are colexified). In this paper, we shall present a large scale empirical study of colexifications among basic vocabulary meanings in the world languages, based on the Automated Similarity Judgment Program (ASJP) database (Wichmann et al. 2013) covering (parts of) the basic vocabularies for well over half of the world’s languages.
Colexification, so defined, is a cover term for both polysemy and homonymy, two well-known linguistic phenomena, and it is no surprise that different aspects of these phenomena have received much attention in recent linguistic work. Some of the basic problems addressed in these efforts include: polysemy and semantic change, cataloguing semantic changes in specific languages or cross-linguistically, cognitive versus culture-specific semantic changes, extensions in specific semantic domains in specific languages or cross-linguistically (body parts, kinship terms, and so on), semantic reconstruction, incorporating polysemy in formal grammar, differentiating polysemy from homonymy (cf. e.g., the collection of papers in Vanhove 2008, Falkum & Vicente (eds.) 2015; also Zalizniak 2008, Urban 2012, Zalizniak et al. 2012, List et al. 2014).
The focus of the present long-term project is the computational construction and subsequent machine investigation of a large-scale typological database of colexifications of basic vocabulary meanings. In this paper we can only briefly sk some aspects and more interesting results. There are some related efforts in the literature. E.g., Zalizniak (2008) and Zalizniak et al. (2012) describe cross-linguistically recurring semantic shifts (=polysemies) in 319 of the languages of the world and manually implement a catalogue in the form of a manually searchable computer database, while List et al. (2014) have automatically built an on-line database of colexifications, based on the Intercontinental Dictionary Series (IDS, Key & Comrie 2007) featuring lexical data for 233 world languages. In the first two papers, however, the authors concentrate on polysemy (relevant for semantic change) rather than more generally on colexification and use no automation either for database construction or subsequent search. List et al. (2014) have indeed computationally built their database of colexifications and their networking but they are not concerned with offering more sophisticated techniques for searching the database. In neither of these works is basic vocabulary the specific focus, and in neither of these is the empirical base so large as that of the Automated Similarity Judgment Program (ASJP) database (see below).
The paper is organized as follows. Section 2 briefly reviews our empirical base and programs. Section 3 summarizes some basic results from the automatically constructed database of colexifications and Section 4 shows some ways to use it. In particular, we propose heuristics (or rules of the thumb) for distinguishing between polysemy and homonymy in a typological database and such for assignment of languages with unknown (or suspect) genetic classification to the same linguistic grouping. Section 5 concludes.
2. The Data and the Program
We explore for colexifications the Automated Similarity Judgment Program (ASJP) database (Wichmann et al. 2013) including the final 100-item list of basic meanings of Morris Swadesh (1971). In our study we included all listed languages except creoles, pidgins, mixed and constructed languages, amounting to some odd 6809 languages, included in 244 top-level language families, according to the Ethnologue classification. The wordlists are not exhaustive for all languages. Forty basic meanings out of the 100-item lists are very representative and include well over half of all known languages, the other sixty are less exhaustive. Below we give the occurrences of each item in the 100-item list in the database, as this allows one to evaluate the actual empirical base for deriving each colexified meaning pair (see Appendix).
The lexical correspondences to the above meanings are given in phonological form in the database.
Before proceeding with the program, we may introduce the following terms:
A colexified meaning pair is the pair of meanings that are rendered in one language by the same lexeme. We shall enclose these pairs in angular brackets, e.g., <person=tree>, <I=we>, and so on.
A colexifier is the specific word-form, or lexeme, which renders the meaning of a colexified pair. We shall enclose colexifiers in square brackets, as in ASJP these are phoneme strings, e.g., [ti] stands for <person=tree> in Kaningi, a Niger-Congo language.
We shall call a colexification model (or simply, a colexification) a lexified meaning pair alongside with its colexifier, e.g., <person=tree> → [ti] (in Kaningi).
We implemented a computer program to discover the colexifications in the ASJP database. The program first constructs all (unordered) pairs out of the 100 meaning items in the wordlist. The logically possible such pairs are 4950 (n choose 2, calculated by the formula n*(n-1)/2, in our case 100*99/2=4950). It is then tested, for each potential colexified meaning pair, whether it is actually realized or not in each of the 6809 languages. These procedures guarantee the exhaustive search for colexifications in the database. For each colexified meaning pair, the supporting languages, their familial affiliation, and colexifiers (i.e., word-forms) are also taken into account, as well as their numbers.
An entry in our colexification database looks like this:
-
• Colexified meaning pair: <person=tree>
-
• Colexifier(s): [re], [te], [ti]
-
• Supporting language(s) with family & colexifier:
-
KANINGI, Niger-Congo (Bantoid branch), [ti]
-
MBOSHI, Niger-Congo (Bantoid branch), [re]
-
NDUUMO, Niger-Congo (Bantoid branch), [ti]
-
TIENE, Niger-Congo (Bantoid branch), [te]
-
• Number of supporting languages: 4
-
• Number of supporting families: 1
-
• Number of supporting colexifiers: 3
This structuring of our colexification database allows straightforward queries to be made to computationally explore it. Any combination of the database parameters, given in italics above, can be queried to retrieve information of interest to the user of the system. E.g., one can discover all colexified pairs valid in only one language family, in three families or in more than 10 families; such valid in more than two languages and having less than 5 colexifiers; such valid only in Indo-European, and so on and so forth. Additionally, a number of subroutines accomplish various counts we found useful in exploring the database, and, importantly, we can unproblematically add more procedures for search as need arises.
3. Summary of the Results
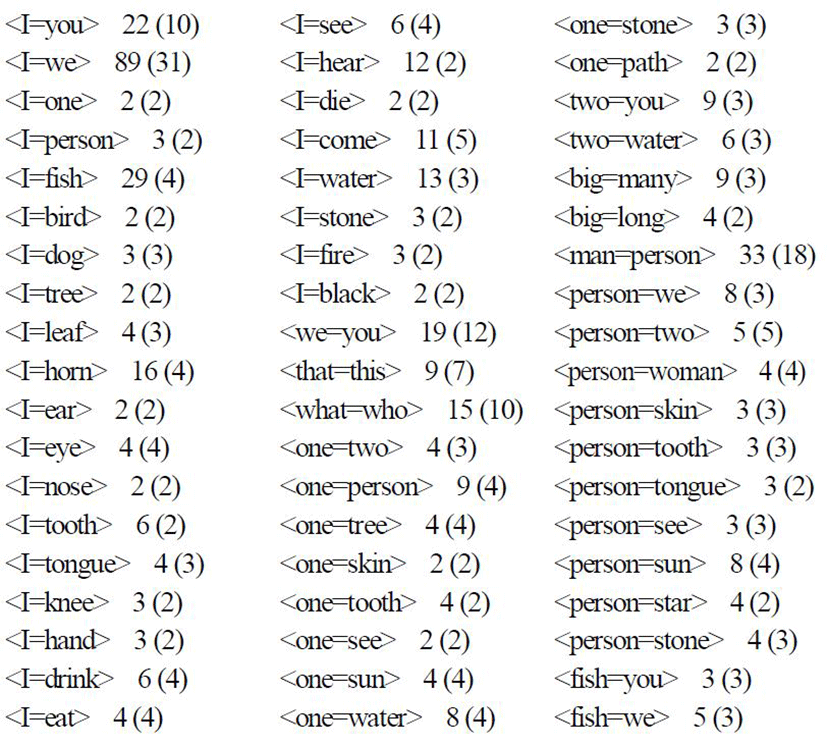
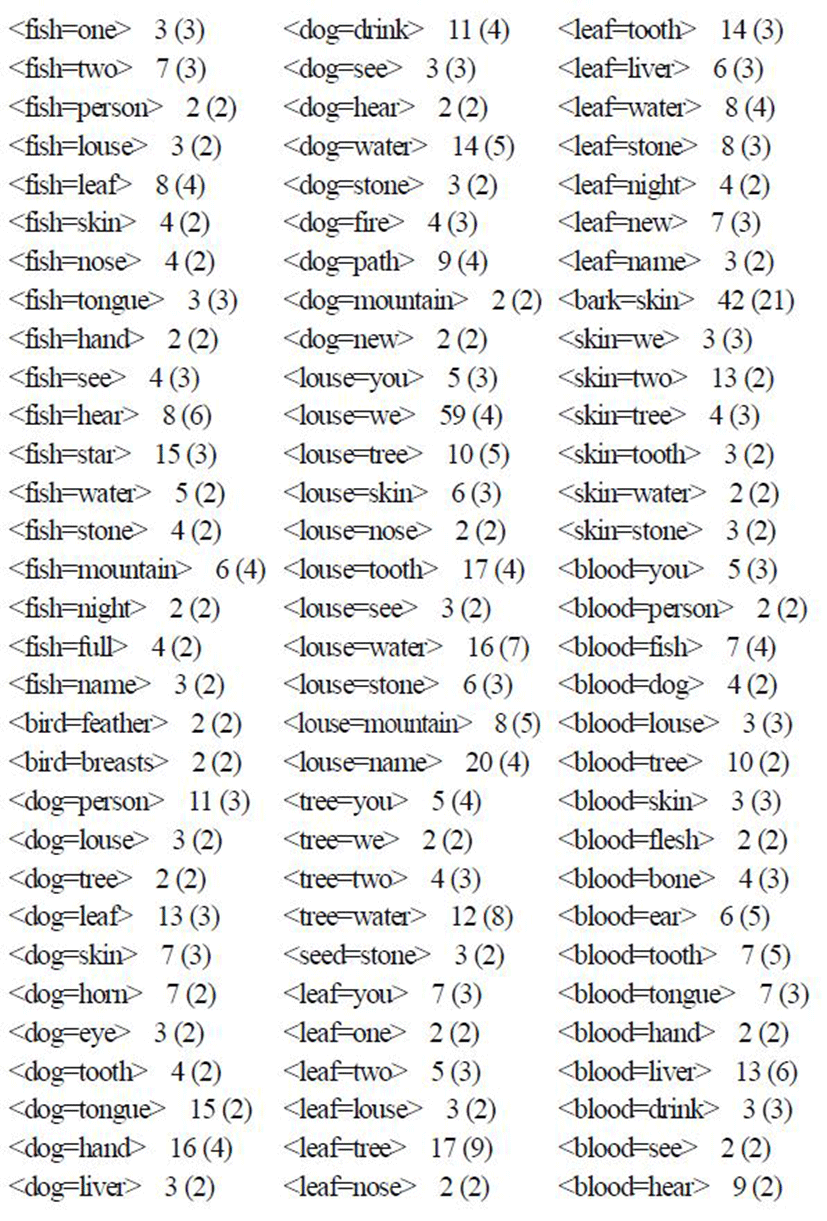
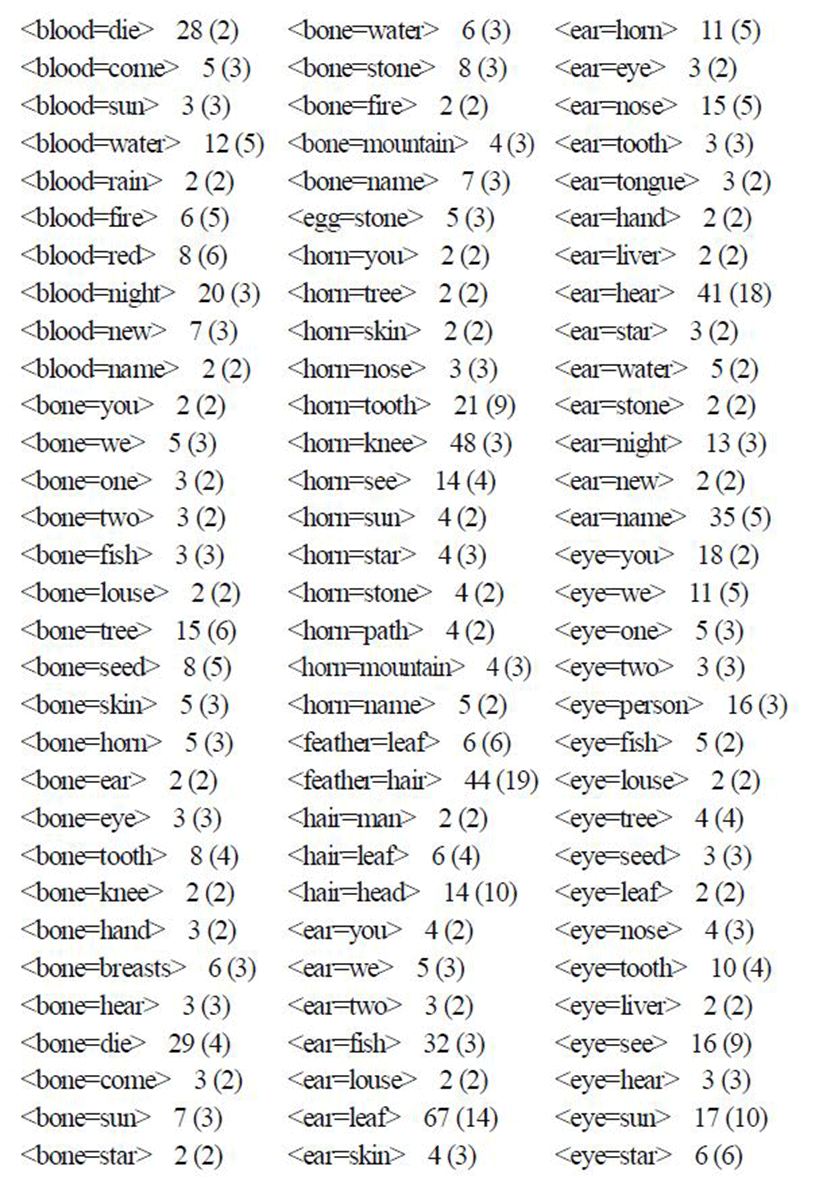
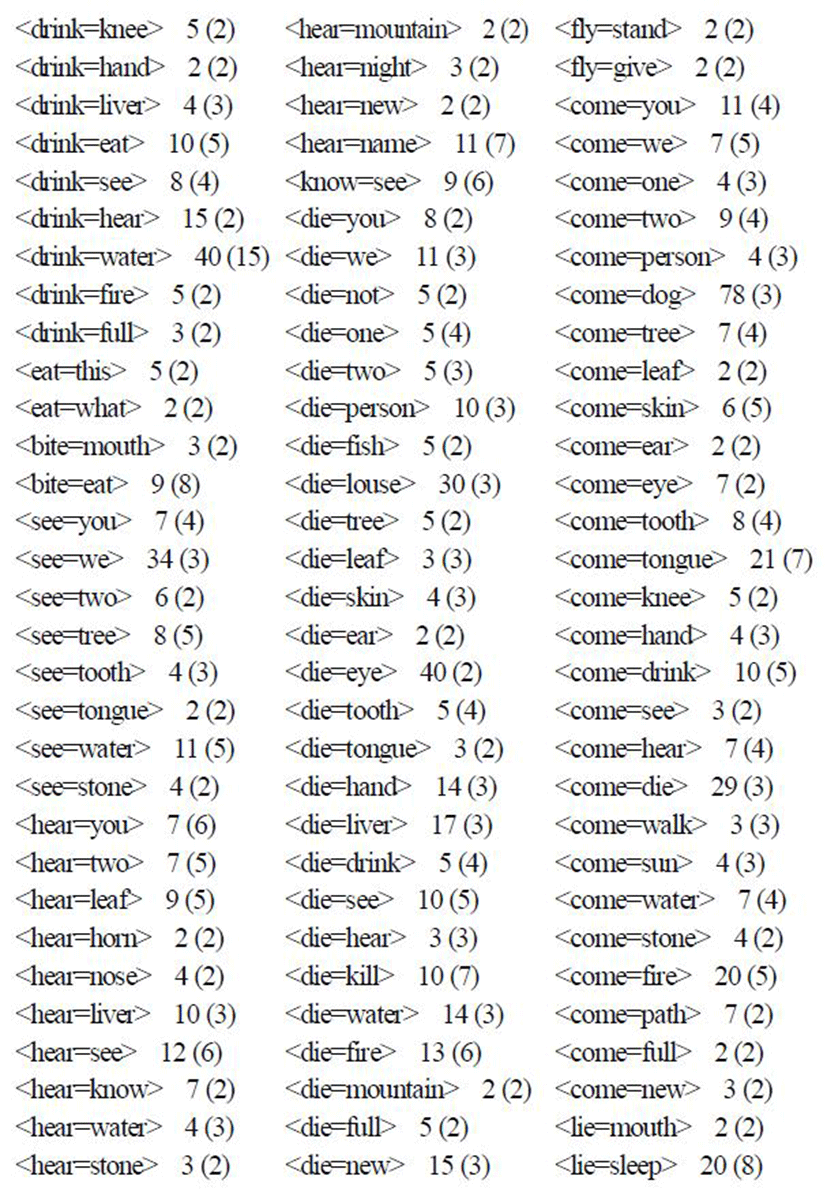
Using our machinery, we constructed a typological database of colexifications in the form shown in the previous section. We show a fragment of the database in the Appendix. For economy of space, we list only the colexified meaning pairs occurring in more than one language, accompanied by the number of supporting languages and top-level families.
Below we summarize the results, specifically in regard to the distribution of colexified meaning pairs in languages and language families.
1) We found 1098 colexified meaning pairs in all out of 4950 theoretically possible from the 100 items in the basic vocabulary list. In other words, more than one fifth of all thinkable patterns are actually realized in at least one of the inspected languages.
2) Some colexified meaning pairs occur in just one or a small amount of languages, while others are somewhat better supported. The number of colexified meaning pairs supported by 1, 2, 3, and so on languages is listed in Table 2.
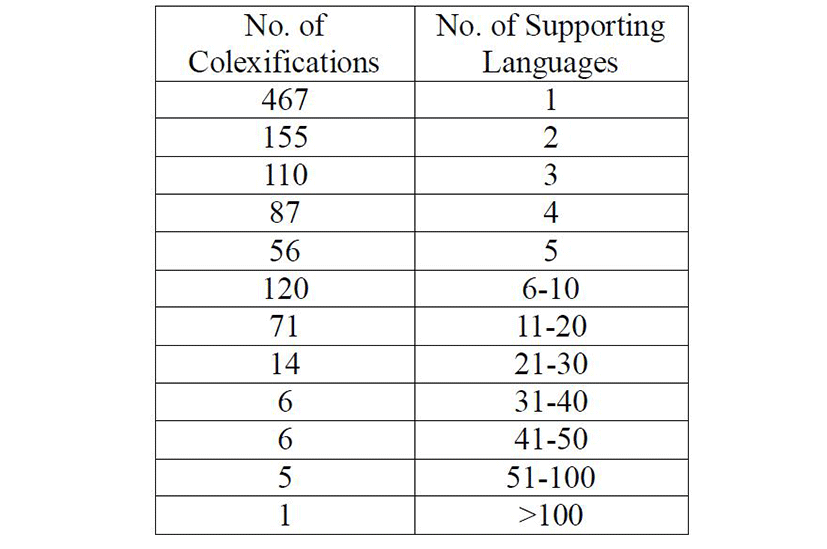
As seen from the above table, by far the greatest number of patterns (467 out of 1098) are found in only one language, i.e., are idiosyncratic to specific languages. 155 models are found in two languages, 110 in three languages, and so on. A smaller number of association pairs are supported in more languages, e.g., 71 patterns are found in the interval 11-20 languages. Only one colexified meaning pair is found in more than 100 languages (this is <mountain=stone> found in 140 languages, amounting to 12.7% of inspected languages for this particular pattern, cf. Table 1). Generally, colexification among basic vocabulary turns out to be a linguistic phenomenon that would appropriately be characterized as “rara” (Wohlgemuth & Cysouw 2010)
3) Some colexifications are present in just one language family, others in two, three or more families. Below we give the distribution of colexifications according to the number of families each is supported by.
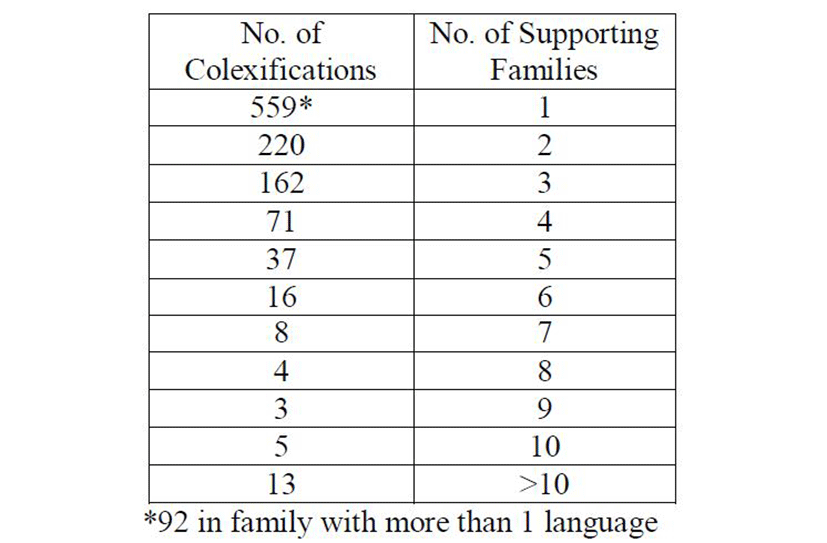
As seen from Table 3, 559 colexified meaning pairs hold in a single language. We will use this fact in the next section as a guideline in assigning genetic membership to a language with unknown or suspect affiliation. 220 meaning pairs occur in 2 families, 162 occur in 3 families, 71 in 4 families and so on. Only 13 meaning association pairs hold in more than 10 language, the highest family support being for <I=we> occurring in 31 families (see Appendix). Generally, we may say that the number of colexification pairs and the number of families supporting them are inversely proportional, i.e., one decreases as the other increases, a fact which could be expected from the analogical distribution of patterns in individual languages, considered in the previous paragraphs.
4. Interpretation of the Results
A typological database of colexifications among basic vocabularies may be put to a variety of uses in fields like semantic change, semantic reconstruction, and historical linguistics more generally. Here we will limit ourselves to considering the problems of distinguishing between polysemy and homonymy and discovering the genetic affiliation of languages with unknown or suspect classifications.
Colexification covers cases of both polysemy and homonymy. It is important to be able to distinguish between the two phenomena in a case of colexification because, while homonymy is less semantically interesting as the result of mere chance coincidence or merging of forms of distinct words, polysemy is the result of real semantic changes and thus reveals general cognitive processes or culture-specific semantic associations. It is no surprise then that it is polysemy rather than homonymy that is subjected to intensive semantic studies.
Which colexifications are cases of true polysemy and hence semantic shifts, and which are homonymous or mere chance form coincidences? In general, this is a complex problem and should be solved individually in each observed case in a specific language. Thus e.g., Modern English arms ‘upper limbs’ and arms ‘weapons’ are homonyms because we know that in Middle English they were distinct words: the word for upper limbs with the form earmes (from Old English earm) and that for weapons armes (from Old French arme) and some phonological processes converged them to a single modern form, viz. arms; whether or not these processes would change the distinct word-forms to an identical form is a fact of purely coincidental nature. In contrast, Modern English arm, meaning either ‘upper limb’ or ‘a support (as on a chair) for the elbow and forearm’ is a single polysemous word in which the first meaning developed (via metaphor) into the second. In other words, the different meanings of homonymous words do not need to be related and are generally not so; in cases of polysemy the different meanings are related by semantic processes (shifts), e.g., metaphor as in the above case, metonymy as in horn ‘animal horn’ or ‘musical instrument’, and so on.
The question now is this: can our database of colexifications help us discriminate (even if approximately) between polysemy and homonymy without recourse to entering into specific historical knowledge pertaining to the individual language at issue? Below we look at several criteria or general heuristics to guide us in a large-scale comparative investigation.
Language, and especially family, support for a colexified meaning pair is an important indicator of polysemy, the greater this support for this pair, the more likely it reflects polysemy rather than homonymy. The obvious idea underlying this guideline is that a repeated occurrence of a meaning association is more likely to be due to some universal semantic shift (i.e., polysemy) rather than due to mere chance coincidence in each language of the forms expressing the colexified meanings (as homonymy would imply).
Below are examples of some of the most common colexified meaning pairs in the ASJP database, quite probably reflecting polysemy (the association pairs are accompanied by the number of supporting languages, followed by the supporting families in brackets):
-
• <mountain=stone> 140 (25)
-
• <I=we> 89 (31)
-
• <ear=leaf> 67 (14)
-
• <fire=tree> 64 (13)
-
• <horn=knee> 48 (3)
-
• <feather=hair> 44 (19)
-
• <bark=skin> 42 (21)
-
• <ear=hear> 41 (18)
-
• <drink=water> 40 (15)
-
• <man=person> 33 (18)
There are however other cases, with reasonable language/family support, which are less certainly polysemous and require further study to find an explanation as to the origin of their ambiguity. Below are such examples we found:
The association pairs with less support in terms of languages and families are more challenging with respect to the determination of whether or not there is true polysemy at issue. The support of an association pair in more than one language family is some sign of true polysemy, but even when a colexified meaning pair occurs in just one family there are some indicators of polysemy. Thus, the presence of several distinct colexifiers in one language family is suggestive of polysemy rather than homonymy. The reason is that the different colexifiers are more likely to be innovations in phonological shape preserving the meaning association (possibly due to some culture-specific traits of the people speaking those languages) rather than be due to the mere chance merging of word-forms of distinct words in each language that have happened in all those languages (as homonymy would imply). In other words, we presume that the meaning association in the pair preserved across the different languages in the family, only the word-forms expressing them innovate with time.
Below are some examples of this type we found exploring the ASJP database.
E.g., some Niger-Congo languages seem to have polysemy rather than homophony in the following colexified meaning pairs: <fish=tooth> in Kensweinsei (Bantoid branch) we have the form [so], in Vagala (Gur branch) we have the distinct form [ɲiŋ], while in Nupe (Nupoid branch) we have the still different [yĩkã]; <blood=nose> in Fang Meke (Bantoid) is rendered by [ʦi], in Guro (Eastern Mande) by the distinct word-form [jæ], and in Lere Gana (Kainji) by the still different [maɲau], and analogically with Bolon (Western Mande) [ju]; <eye=horn> in Bum B Cameroon (Bantoid) has the form [sæ], Senuoufo Tagwana (Gur) the distinct form [ɲala].
Similar considerations hold in two Austronesian languages: <foot=hand> in Samoan (Oceanic branch) is denoted as [aɁao] and in Yapese (Yapese branch) as [rifrif], two apparently distinct word-forms. Cf. also <earth=liver> in Aguacateco Aguacatan (Mayan) [ʦoʦ] and Uspanteko (Mayan) which has the very different form [ulew].
Such presence indicates polysemy rather than homonymy for reasons similar to the previous heuristic. If a language chooses to coin a new form to express some meaning, this meaning, being firmly associated with another meaning in a colexification pair, carries over to the new word-form. Put differently, the linguistic process at work is an innovation in form preserving the stable meaning association, or polysemy.
E.g., the colexification pattern <all=many> occurs only in Nunggbuyu (Australian) and is expressed by the synonymous pair of apparently distinct forms [warawindi] and [dalun], therefore signaling polysemy in that language.
The possibility to account for a colexification by appealing to known semantic changes (metaphor, metonymy, narrowing, broadening, and so on), which generally reflect universal cognitive associations, apparently gives a preference to interpreting a colexification as a case of polysemy rather than homonymy.
These heuristics can operate collectively and thus present stronger support for an interpretation of a colexified meaning pair as a case of polysemy.
E.g., we may consider the colexified meaning pair <mountain=stone>, registered in the database in 144 languages from 25 families. This strong support in terms of languages and families indicates polysemy (by heuristic 1). The semantic association between these meanings is a clear case of a semantic shift by metonymy (heuristic 4). Below we give examples further strengthening our interpretation of the colexification as a case of polysemy, based on the other two criteria.
In the Niger-Congo family the language Bua (Adamawa branch) has the form [ta] for <mountain=stone>, Biali (Gur) has [tali], Ditammari (Gur) [yatãda], Ekpetiama (Ijoid) [ugu], Ziriya (Kainji) [kafau], and so on, all forms apparently non-cognate and derived from different parent forms (heuristic 2).
In the Nilo-Saharan family we have an analogical situation: for <mountain=stone> the language Kaba Deme Sara (Bongo-Bagirmi branch) has the form [ko], Kabba (Bongo-Bagirmi) has the distinct form [jer], Berti (Eastern Saharan branch) the form [wi], Gule (Koman branch) the form [of], Uduk (Koman) [woʃ], Gbaya (Kresh) [angba], Mangbetu (Mangbeti) [nekopi], Andri (Moru-Maadi) [univa], Miza (Moru-Maadi) [baraŋwã], Anyuak (Nilotic) [kidi], Nuer (Nilotic) [p ͪ æ̴̴̃m], and so on.
In the Australian family, the language Diyari designates the colexification pattern <mountain=stone> by [mada], the languages Gangulu by [bari], Ganggalida by [kamara], Nyangumarta by [wanku], Yanyuwa by the alternative non-cognate colexifiers [buluruluru] and [daŋgã] (i.e., the latter also by heuristic 3), and so on.
In general, there are numerous examples of this type in our database of colexifications.
The study of colexifications in different languages may have different implications for historical linguistics. E.g., Croft et al. (2009) address the problem of quantifying semantic change for the purposes of choosing among alternative historical reconstructions. To this end, they conduct a typological study of word polysemy among basic vocabulary items in order to find the frequencies of the different meanings in polysemous words. They investigate 22 concepts denoting natural objects in the Swadesh list across a typological sample of over 50 languages.
While the above approach assumes already available hypotheses regarding genetic affiliation, we explore the possibility, based on our colexification database, to guess membership of two languages in the same language family. We propose a heuristic to this effect, derived empirically from the found colexifications. Thus, we found that there are 6426 shared colexification models (or simply, shared colexifications) between a pair of languages, i.e., cases in which two languages have the very same colexifying word-form for the same colexified meaning pair. Only 47, or 0.7% (47/6426) of these shared colexifications were found to hold in two languages belonging to different language families, while 99.3%, were found to hold in the same language family. (It should be borne in mind, however, that the matching of colexifiers may be somewhat less precise in some cases, owing to the fact that the ASJP database slightly simplifies the phonetic representation of word-forms.) In consequence, shared colexifications seem like a reliable indicator of genetic affiliation and can be used as a heuristic to this effect: finding shared colexifications signals shared genetic membership with a probability of 99.3%. This high reliability of our criterion for same family membership should not be surprising, as the criterion implies that the two languages share two cognate words plus a colexification for these two meanings.
Below are some shared colexifications between language pairs of different language families out of those we found inspecting our colexification database.
(1) Shared colexification <I=horn> → [ku] in Tai-Kadai & Hmong-Mien
-
• Proto Kadai (Tai-Kadai) & (Hmong-Mien)
-
• Proto Kadai (Tai-Kadai) & Proto West A Hmong (Hmong-Mien)
-
• Proto Kadai (Tai-Kadai) & Shimenkan Hmong (Hmong-Mien)
-
• Proto Kadai (Tai-Kadai) & Tak Hmong (Hmong-Mien)
(2) Shared colexification <come=tongue> → [ma] in Tai-Kadai & Austronesian
-
• Laha (Tai-Kadai) & Selaru (Austronesian, Central Malayo-Polynesian)
-
• Fangcun Mak (Tai-Kadai) & Selaru (Austronesian)
-
• Kam (Tai-Kadai) & Selaru (Austronesian)
-
• Kam Zhanglu (Tai-Kadai) & Selaru (Austronesian)
-
• Mak (Tai-Kadai) & Selaru (Austronesian)
-
• Sui Jung Chiang (Tai-Kadai) & Selaru (Austronesian)
-
• Sui Li Ngam (Tai-Kadai) & Selaru (Austronesian)
-
• Tiangzhu Shidong Northern Dong (Tai-Kadai) & Selaru (Austronesian)
-
• Zhanglu Dong (Tai-Kadai) & Selaru (Austronesian)
The above two shared colexifications, suggesting pairwise relatedness between Austronesian, Hmong-Mien and Tai-Kadai do not look like wild guesses but rather seem to corroborate a well-known (but still controversial) hypothesis by Paul K. Benedict (1976), who linked these languages in an Austric stock. The Austric hypothesis was actually first proposed by Wilhelm Schmidt, who initially linked only Austroasiatic and Austronesian, suggesting Hmong-Mien as a further possible member of the stock.
Most of the other found shared colexifications do not seem to reflect any suggested relationships in the literature, but we may mention some for consideration by linguists known as “lumpers”, who spend efforts in trying to group languages into larger genetic groupings, or superfamilies.
E.g., a number of pairwise shared colexifications were found between Niger Congo languages and Austronesian and Sepik languages (these could simply be chance coincidences owing to the very large number of languages in these families (esp. Niger Congo and Austronesian) in the ASJP database).
(3) Niger-Congo and other families
-
•<I=we>→[mi]Nyambeengge (Niger-Congo) & Jarawa (Austronesian)
-
•<I=we>→[ŋa]Baka 2 (Niger-Congo) & Raute (Sino-Tibetan)
-
•<I=come>→[na]Baatonum (Niger-Congo) & Lorediakarkar (Austronesian)
-
•<I=come>→[na]Baatonum (Niger-Congo) & Shark Bay (Austronesian)
-
•<come=fire>→[ja]Bongili (Niger-Congo) & Maprik (Sepik)
-
•<come=fire>→[ja]Bongili (Niger-Congo) & Ngala (Sepik)
-
•<come=fire>→[ja]Bongili (Niger-Congo) & Nyaura (Sepik)
-
•<come=fire>→[ja]Bongili (Niger-Congo) & Wosera (Sepik)
-
•<come=fire>→[ja]Bongili (Niger-Congo) & Yelogu (Sepik)
-
•<come=fire>→[ja]C831 Ilebo (Niger-Congo) & Maprik (Sepik)
-
•<come=fire>→[ja]C831 Ilebo (Niger-Congo) & Ngala (Sepik)
-
•<come=fire>→[ja]C831 Ilebo (Niger-Congo) & Nyaura (Sepik)
-
•<come=fire>→[ja]C831 Ilebo (Niger-Congo) & Wosera (Sepik)
-
•<come=fire>→[ja]C831 Ilebo (Niger-Congo) & Yelogu (Sepik)
-
•<come=fire>→[ja]Mboshi Bunji (Niger-Congo) & Ngala (Sepik)
-
•<come=fire>→[ja]Mboshi Bunji (Niger-Congo) & Nyaura (Sepik)
-
•<come=fire>→[ja]Mboshi Bunji (Niger-Congo) & Wosera (Sepik)
-
•<come=fire>→[ja]Mboshi Bunji (Niger-Congo) & Yelogu (Sepik)
-
•<come=fire>→[ja]Bongili (Niger-Congo) & Boikin (Sepik)
-
•<come=fire>→[ja]C831 Ilebo (Niger-Congo) & Boikin (Sepik)
-
•<come=fire>→[ja]Mboshi Bunji (Niger-Congo) & Boikin (Sepik)
-
•<come=fire>→[ja]Mboshi Bunji (Niger-Congo) & Maprik (Sepik)
-
•<see=you>→[na]Lama (Niger-Congo) & Dafang (Sino-Tibetan)
Other cases of shared colexifications may also be mere coincidences, this time not due the large number of inspected languages, but owing to more common colexified meaning pairs like <I=we>, <mountain=stone>, <drink=water>. Another possibility for explanation in some cases may be areal closeness, as e.g., the third example involving languages from North America below.
(4) Others
-
•<I=we>→[ni]Hausa (Austro-Asiatic) & Montagnais (Algonquian)
-
•<I=we>→[ni]Hausa (Austro-Asiatic) & Wintu (Penutian)
-
•<I=we>→[ni]Montagnais (Algonquian) & Wintu (Penutian)
-
•<mountain=stone>→[wi]Berti (Nilo-Saharan) & Yavapai (Hokan)
-
•<mountain=stone>→[kau]Buduma (Austro-Asiatic) & Kanuri (Nilo-Saharan)
-
•<drink=water>→[ma]Tirma (Nilo-Saharan) & Vilela (Lule Vilela)
Can the colexified meaning pairs alone signal genetic affiliation? In Table 3 we saw that there are 559 association pairs that hold in a single language family, 92 of which hold in more than one language in that family. This fact apparently can be suggestive of affiliation: if a colexified meaning pair is idiosyncratic to a language family, then a language with unknown (or suspect) membership could be assigned to that family if it happens to have the same meaning association. Colexified meaning pairs with greater support in terms of languages will have more weight in making this decision.
Below we list meaning pairs that occur only in one language family, and are supported at least by 5 languages. In order to be more precise regarding membership assignment, we give the full lineage of the groupings rather than only the top-level language membership (indicated in bold in the starting example for a family). Also, in the following list we give the number of supporting languages and the number of all languages in the lineage.
(5) Colexifications occurring in a single family (≥5 languages)
-
• <leaf=path> : [Niger-Congo, Atlantic-Congo, Volta-Congo] (7 from 1286 languages)
-
• <ear=person> : [Niger-Congo, Atlantic-Congo, Volta-Congo, Benue-Congo, Bantoid, Southern, NarrowBantu] (13 from 752 languages)
-
• <ear=tree> : [Niger-Congo, Atlantic-Congo, Volta-Congo, Benue-Congo, Bantoid] (12 from 892 languages)
-
• <breasts=two> : [Niger-Congo, Atlantic-Congo, Volta-Congo, Benue-Congo] (13 from 1075 languages)
-
• <die=dog> : [Niger-Congo, Atlantic-Congo, Volta-Congo, Benue-Congo, Bantoid, Southern] (8 from 876 languages)
-
• <fire=new> : [Niger-Congo, Atlantic-Congo, Volta-Congo, Benue-Congo, Bantoid] (18 from 892 languages)
-
• <full=liver> : [Niger-Congo] (7 from 1455 languages)
-
• <drink=louse> : [Mayan] (23 from 121 languages)
-
• <give=tongue> : [Mayan, Yucatecan-Core Mayan] (9 from 114 languages)
-
• <earth=liver> : [Mayan, Yucatecan-Core Mayan, K'ichean-Mamean] (5 from 82 languages)
-
• <louse=new> : [Sino-Tibetan] (9 from 273 languages)
-
• <nose=one> : [Khoisan, Southern Africa, Central] (8 from 16 languages)
-
• <tooth=two> : [Austronesian, Malayo-Polynesian, Central-Eastern Malayo-Polynesian, Eastern Malayo-Polynesian, Oceanic, Central-Eastern Oceanic, Remote Oceanic, North & Central Vanuatu, Northeast Vanuatu-Banks Islands, Epi, Lamenu-Baki] (6 from 13 languages)
-
• <liver=new> : [Hmong-Mien] (10 from 47 languages)
-
• <burn=eye> : [Trans-New Guinea, Finisterre-Huon, Huon, Western] (5 from 10 languages)
It turns out that the Niger-Congo family has 7 idiosyncratic meaning association pairs, Mayan 3, Sino-Tibetan, Khoisan, Austronesian, Hmong-Mien and Trans-New Guinea 1 pair.
In our computational exploration of ASJP, we came across the following intriguing case: the language isolate Sumerian, the language of ancient Sumer, which was spoken in northern Mesopotamia (modern Iraq), turned out to share the colexified meaning pair <blood=die> with Sino-Tibetan, and particularly with 27 languages of Tibeto-Burman origin, and these are the only languages in ASJP that have this meaning association. This is a finding of some interest because the classification of Sumerian is highly controversial and a wide variety of proposals have been made concerning its linguistic affiliations, including Munda, Dravidian, Kartvelian, Uralic, Basque, Nostratic, Sino-Tibetan (for the various proposals, cf. e.g., Zakar 1971, Bombard 1984, Diakonoff 1997, Braun 2004, Parpola 2007). Our finding seems to corroborate the hypothesis of the link of Sumerian to Tibeto-Burman, proposed by Braun (2004).
It should be strongly emphasized here that our guidelines are only suggestive of genetic membership and should not be taken at face value. They only provide hints that require further investigations, possibly with worthwhile outcome.
5. Conclusions
In the paper we presented a typological database of colexifications among basic vocabulary, computationally derived from the ASJP database. We found 1098 colexified meaning pairs in all out of 4950 logically admissible from the 100 items in the basic vocabulary list. In other words, more than one fifth of all thinkable patterns are actually realized in at least one of the languages in the database. Some potential applications of the inventory of colexifications were proposed. Some heuristics were introduced pertaining to distinguishing of polysemy from homonymy in a typological database, as well as such related to the determination of common membership of two languages in the same language family. In particular, it was found that shared colexifications corroborate the postulation of the Austric stock and the attribution of Sumerian to the Tibeto-Burman language family.
Our database of colexifications among basic vocabularies provides a solid starting point for deeper analyses of various problems in semantic change, semantic reconstruction, and historical linguistics more generally.