
1. Introduction
Most theories of phonology assume a universal set of features and phonetic definitions for forming rules and representations. Chomsky & Halle (1968) offer one theory, proposing about 40 features, which are value-attribute pairs conjoined into matrices.
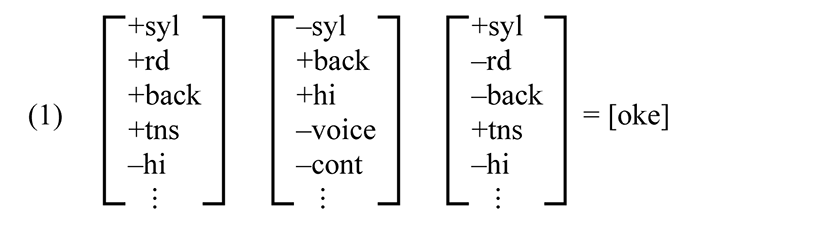
Autosegmental phonology modifies this in two primary ways. First, features relate to each other by dominance as well as precedence relations. Features also may be simple attributes without distinctive values. In most autosgmental theories, especially UFT1 (Clements & Hume 1995), feature definitions are more coarse-grained than in SPE, so that “coronal” may refer to frontness of vowels and consonants, or to raising of the tongue blade in consonants. Nevertheless, most versions of autosegmental phonology assume that languages draw on a fixed set of phonetically-defined universal features.
The premise of a universal inventory of representational primes with intrinsic substantive content has characterized most phonological theories, especially in the generative tradition. This is consistent with the earlier policy of attributing as much as possible to UG, minimizing the content of specific grammars. Under this approach, when a child is exposed to the English word “cat”, a crosslinguistically-invariant feature representation is automatically assigned, based on the acoustic facts which the child encounters.
Many of the substantive premises characterizing modern phonology have been called into question in the Substance Free framework, see in particular Hale & Reiss (2008)—however, it is important to acknowledge that Hale & Reiss do not question, and do affirm, the commitment to universal phonetically-fixed features, even though the phonology does not have direct access to the phonetic definitions of features. RSFP, developed in Odden (2006), Blaho (2008) and Odden (To Appear) completely cuts the connection between features and phonetic content. This approach holds that features are devoid of all phonetic content, and (along with Hale & Reiss) holds that no aspect of phonology refers to the phonology-external physical substance of segments.
While specific features such as [coronal], [voice] and so on are not part of UG in RSFP, UG does provide the formal mechanisms which are the basis for a child learning from the facts of a language those features that are required in order to describe the language. UG specifies what it means to be the grammar of a language, it does not say what the specific content of a grammar is. A grammar is a system of rules of a particular type, which operate on representations that have a specific nature. For the purposes of phonology, the crucial claim is that a representation is a tree-like network of privative features, familiar from autosegmental phonology. The concept of “rule” reduces to insertion or deletion of a node or dominance relation, again adopting the standard autosegmental theory of simple rules. In other words, RSFP agrees that (2a) is a possible representation and (2b) is a possible rule.
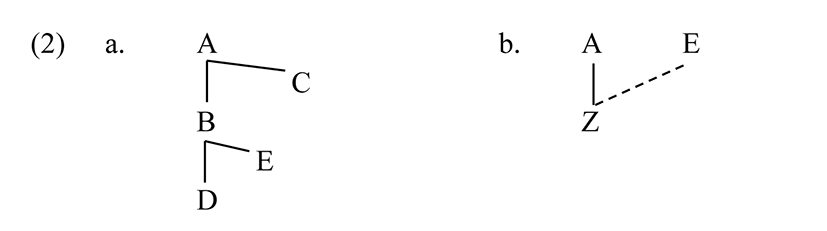
It is not enough to just say “children learn the features required for a language”, we need a theory of how this is done. Odden (To Appear) sets forth the logic of feature learning in rule-based RSFP, illustrated with the discovery of the features necessary for constructing a grammar of the Bantu language Kerewe. In this paper, I demonstrate the further applicability of those principles, looking at the phonology of Logoori, a Bantu language of Kenya.
2. The Logic of Feature Learning
The premise of RSFP (and generative phonology, in general) is that any segment of a language is a conjunction of features, that any representation is a sequence of such feature structures with possible relations between segments, and that rules refer to specific segments by identifying the feature combinations which identify the segments which are included versus excluded as terms in a rule. RSFP departs from universal substance-based theories of phonology in not invoking as part of UG universal phonetic detectors which automatically assign features to language sounds. Instead, the choice of features for a language is based on the logic of rule-learning. In order for a child to learn that the language sounds {p, t, tʃ, k} have a feature in common, and that the pairs {p, b; f, v; tʃ, dʒ; x, γ} have a relationship governed by a feature, they use the same logic as is used to detect from the facts of the language that /p, t, tʃ, k/ become [b, d, dʒ, g] after [m, n, ŋ] (a grouping which justifies positing a third feature). The logic applied to these learning puzzles is that changes in segments (whose feature content is yet to be determined) are observable as a function of surrounding segments. The child knows that segment classes are expressed in grammar by feature expressions, therefore the child knows that the pattern of segment classes in the grammar reveals the features necessary for the language.
We can demonstrate this reasoning with a phonological rule in Logoori. The voiceless stops /p, t, tʃ, k/ become [b, d, dʒ, g] after [m, n, ɲ, ŋ], seen in many examples in the language, especially the following verb paradigm with the 1s subject prefix /N/. The distinction /p, t, tʃ, k/ versus /b, d, dʒ, g/ is maintained after a vowel (Class 1 subject prefix /a-/ or 1st plural object prefix /kʊ-/), and is neutralized to [b, d, dʒ, g] after the 1s subject prefix /N/.

A child is exposed to this fact pattern, and must analyze all of the relevant patterns of the language into a system of rules and representations. The contribution of UG is to say what a formally-possible rule or representation is. Whether or not features are binary or privative is a fixed fact of UG, and is a major contributor to limiting the hypothesis space for stating rules. I assume a privative model of features—see Odden (To Appear) for discussion of the arguments for that conclusion. UG specifies what form a rule takes: a child does not and cannot “learn” that an operation should be expressed with rules versus constraints versus exemplars, nor does a child have to learn whether to use autosegmental theory vs. SPE theory. I assume a minimalist version of autosegmental representations, without the substance-based universal properties of features commonly found in autosegmental research (e.g., “Place always dominates Coronal”). Finally, I assume as a basic premise of learning theory that the child selects the simplest analysis consistent with the facts.
The child induces a general fact-pattern which subsumes the examples in (3) as well as myriad other examples that it has encountered. A child knows that the segments {p, t, tʃ, k} become {b, d, dʒ, g} after {m, n, ɲ, ŋ}. This leads to the conclusion that {p, t, tʃ, k} have something in common, because they are picked out by a rule (which refers to that thing), and {m, n, ɲ, ŋ} have something in common because those segments cause the change. Rules are based on general properties of sounds—features—and not arbitrary lists. The child observes the analogical relations {p:b::t:d::tʃ:dʒ::k:g}, and unifies these facts into a formal autosegmental rule, schematically (4).

The trigger segments have a feature which is assigned to the target, and the result is that one class of input segments changes to a different class as expressed in the above analogical relation. The logic of feature-learning in RSFP is thus:
The data give evidence for a rule.
The rule positively refers to classes of segments and relations between segments.
References to classes of segments are realized in rules by feature expressions.
⸫ The necessary feature expressions of the rule system are the basis for learning what features the language employs to represent its segments.
3. What Does UG Contribute?
It is well beyond the scope of this paper to give a complete theory of phonological UG, but it is important to at least sketch the basic assumptions imputed to UG, since the entire logic of feature learning depends on there being a theory of rules and representations, which are the basis for learning what features exist in a language. See Odden (2013, 2021) for more discussion of the logic of theorizing about UG. This section gives a brief summary of the minimal assumptions required for feature learning.
The main split in the theory of representations is between SPE theory and Autosegmental theory. In SPE theory, a representation is an ordered sequence of segments, and a segment is an unordered set of value-attribute pairs for a list of features provided by UG. Autosegmental representations are composed of nodes of different types, where instances of the same type (“coronal”) enter into a precedence relation, and nodes of different types potentially enter into a dominance relation (“coronal” dominates “anterior”). Segments do not strongly define the domains of feature associations. The arguments for the Autosegmental model are well-enough established that they need not be reviewed here.
The Autosegmental approach also encompasses many specific proposals, which primarily involve adding more claims to the minimal “precedence/dominance of nodes” presented here. Works such as Sagey (1986) and Clements & Hume (1995) make numerous substantive claims (often repeating analogous claims of SPE theory) that UG provides specific nodes such as “nasal”, “voice”, “coronal”, also “Place”, “Laryngeal” and so on which are termed “organizing” nodes. There are many claims about dominance relations built into the theory—“Place immediately dominates Coronal”, “Coronal immediately dominates anterior”, “Laryngeal immediately dominates voice”, “Manner immediately dominates continuant” and so on. The difference between these substanceful accounts and RSFP is that RSFP eliminates from UG all of the stipulations as to what nodes exist, and what dominates what. The same nodes and relations may well exist, but they are learned based on grammatical evidence. Such structures are universally possible because a representation is a set of dominance and precedence relations, and they will be language-specifically necessary when the facts of the language compel such structures.
In RSFP, names like “V-place”, “Laryngeal” are labels of convenience without physical interpretation. A node like “V-place” simply means that certain other nodes form a constituent and therefore can be acted on as a unit. Substance-dependent theories of features typically specify a narrow (typically unique) set of dominating nodes, e.g., “Coronal is only dominated by Place”, or for some nodes in UFT “Coronal is only dominated by C-Place or V-place”. RSFP has no such mandates. If the facts of a language motivate it, it is possible for Place to dominant [voice].
The theory of rules associated with RSFP is also very sparse. The difference between the RSFP approach and Autosegmental theory is much smaller, because Autosegmental theory took it to be a desideratum to minimize the content of rule theory at the cost of enriching the theory of representations. The core claim about rules is that a rule may insert or delete a node or dominance relation—a feature may be deleted or inserted, an association relation may be added (spreading) or deleted (delinking). Since RSFP is a theory of representations and not a theory of rules, it is technically outside of the domain of RSFP to inquire whether anything else is required in the theory of computations. Nevertheless, the principles of FP that lead to RSFP also lead to a very simple theory of rules, one which has just simple rules, without the complex system of auxiliary actions often associated with autosegmental rule-application (e.g., the OCP, automatic resyllabification, structural rearrangements under the guise of structure preservation), or the complicated rule algebra associated with SPE theory. While the approach eschews a large built-in inventory of automatic and especially “parametric” principles such as the OCP, there is ample theoretical room for strong structural universals such as the No-Crossing constraint.
Rule (4) = (5a) is of a few rule-types possible in this theory, one which progressively spreads a feature from segment to segment. Other rule types include regressive spreading of a feature from segment to segment (5b), deletion of a content node after some structure (5c), or deletion of an association relation in a segment when followed by some other segment (5d).
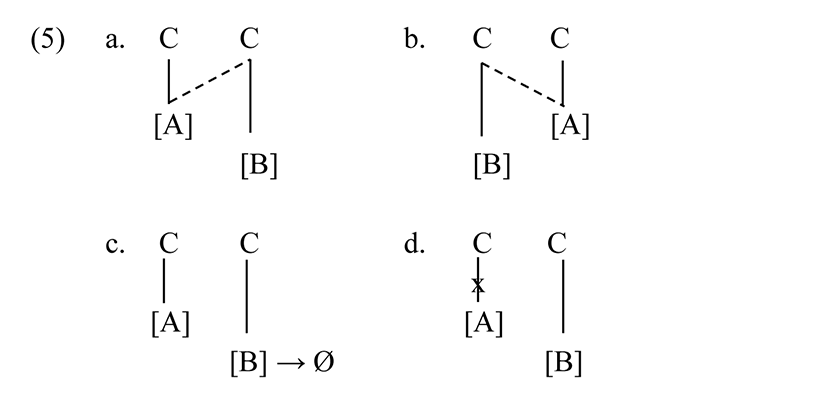
As in substance-based phonology, whether a rule of the general form (5a) spreads voicing from nasals to stops, nasality from consonant to vowel, or vowel height from mid vowels to high vowels depends on the particular node types specified in the rule.
Two facts of grammar determine the system of features learned. First, the system of features must suffice to encode the segments that are in the phonology. If a language has {p, t, k, b, d, b}, some unique set of features is assigned to each of them. This is different from saying that features must differentiate the “phonemes” or “contrasts” of a language. “Phoneme” traditionally refers to a subset of the phonological segments of a language, where properties are factored out just in case they can be supplied by surface-oriented rule. “Phonemes” are thus distinguished from “allophones”. The segments of the phonology of a language are, put simply, all segments that exist in the phonological component, be they underlying, in the output of the lexical level, or at the tail end of the phonological derivation. If aspirated consonants exist in the phonology of English, then there must be distinct representations for all of [p, pʰ, t, tʰ, k, kʰ]. This does not mean that all physical differences produced by speakers correspond to distinct phonological segments. If, as argued by Cohn (1990), English phonology only has oral vowels and the seeming existence of nasal vowels is due to non-phonological principles of phonetic implementation, the phonological grammar of English only needs features for [i, ɪ, e, ɛ] etc. and not, additionally, [ĩ, ɪ̃, ẽ, ɛ̃] etc.
Second, all phonological rules refer to classes of segments by referring to a network of dominance and precedence relations between nodes—features are simply a sub-type of node. The fundamental principle of RSFP is that the set of nodes (features) learned for a language is whatever system yields the simplest grammar for the language. This means “simplest grammar” in the integrated sense: phonological simplicity cannot be gained for free by unconscionably complicating the phonetic or morphological grammars. When some subset of segments functions as a group in a phonological rule, a feature expression is called on by the grammar to encode this fact. The system which yields the fewest features and simplest set of specifications in rules is the system learned by the child.2
4. Logoori
Logoori is part of the Luhya subfamily of Bantu, and is spoken primarily in Vihiga county of Western Kenya. There are many minor dialectal differences in the language, such as whether regressive vowel harmony usually is applied versus usually is not applied, or whether the “augment” prefix on nominals (a vowel) is usually phonologically deleted versus not deleted. Most variation either regards optionality in rule application, or phonetic details of how certain segments are pronounced (whether “r” is closer to IPA [ɾ] versus [ɺ], whether the front nasal is pronounced [nʲ] or [n̪]). The data presented here are tilted in favor of the South Maragoli realization, but are found in many parts of the Logoori-speaking community.
The following phonetic segments exist in Logoori.
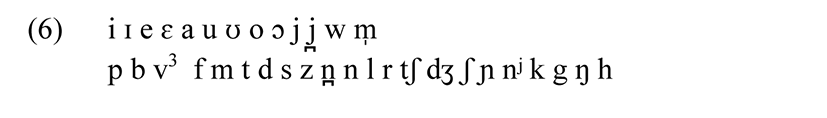
Vowels can be long, notated by double-writing for long vowels (kɔ́dɛ́ɛka ‘to cook’). H tone is indicated with acute accent on syllabic segments. Tone and vowel length do not figure into the present analysis. Geminate consonants always derive from CVC sequences via optional deletion of V and assimilation of the first consonant, for example [ɪddíidʒi] ‘wall’ from /ɪridíidʒi/. C-clusters other than NC exist in a few loanwords such as [ɛbɔ́ɔ́sta] ‘post office’, but there are only a few older loanwords such as [ɪskʊ́ʊrʊ, ɪsʊkʊ́ʊrʊ] ‘school’ with seemingly variable epenthesis. The analysis does not depend on allowing or excluding sequences like [st, sk, tr] etc.
A complete phonology of Logoori is beyond the scope of this paper, so I stipulate a relatively standard analysis of suprasegmentals. Segments are organized into syllables, long vowels are single segments with two moras, syllable onsets have a consonant which may be preceded by a nasal, and (save for a few loanwords) there are no coda consonants. There are two analyses of (apparent) consonant plus glide sequences, as observed in ɪkɪ́vwɪ́ ‘fox’, tja ‘fear!’, ɪdwaasi ‘milk cow’, ɪkɪ́vjá ‘metal’, kwɛɛsa ‘pull!’. Either the onset consonant is followed by a glide, or consonants have fronted and labialized variants (ɪkɪ́vʷɪ́, tʲa,ɪdʷaasi,ɪkɪ́vʲá, kʷɛɛsa).
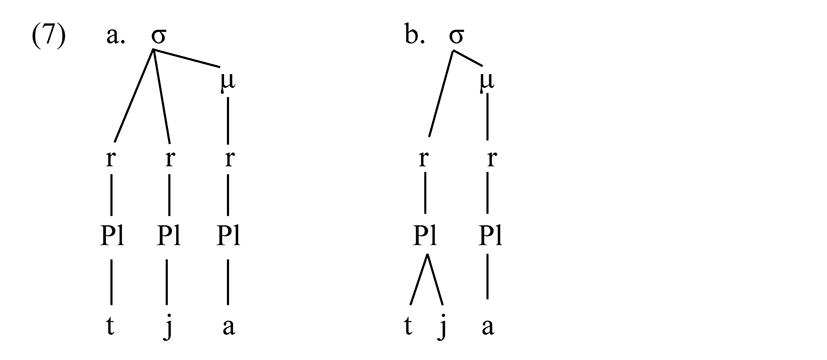
The grammatical difference between these representations lies in the statement of possible onsets where (7a) allows a second more restricted sequence of nodes, and in the statement of the content of segments where (7b) allows more structure under the root node. Determining which system of licensing is the simplest requires a fleshed-out theory of such rules, which has not been fully developed, but there is no clear formal advantage to one account versus the other. I adopt the secondary articulation approach, but a detailed comparison of the two theories would be necessary to establish that this is the correct approach.
Syllabic [m̩] can always be derived from /mV/ by optional rules deleting V, thus [ʊm̩banɔ] ‘knife’ derives from /ʊ-mʊ-vanɔ/. The prosody of syllabic and geminate consonants is not analyzed here. The singleton liquid transcribed here as [r] (more properly [ɾ] in IPA since it is never a trill) could equally well—or poorly—be transcribed as [ɺ, ɽ]. When geminated, it more clearly sounds like [ll], thus by convention the singleton liquid will be written as [r] and the geminate as [ll]. There is no evidence that the two sounds are phonologically distinct.
We have already seen evidence in (3) that /p, t, tʃ, k/ → [b, d, dʒ, g] after a nasal. In positing a rule, we must answer some data questions. What triggers the rule? Nasals, and only nasals do. Do other segments change similarly? The input class is potentially larger, including /v, h, w, r, j̪, f, ʃ/, which become respectively [b, b, b, d, z, bʷ, bʲ].

The class of output segments in (3) partially overlaps the class found in (8), and the simplest analysis results from subsuming both sets under one rule. Not all consonants are modified in this context, because certain consonants instead cause the nasal to delete (e.g., /n-sétʃi/ → [sétʃi] ‘I laughed’). The relevance of deletion is that hardening-voicing applies to remaining nasal + consonant sequences.
This leaves us with the question of the trigger class. All observed triggers are nasals, but this is largely due to the restricted nature of CC clusters. There are non-nasal consonants in clusters of loanwords like [ɛbɔ́ɔ́sta] ‘post office’, [kɔndákta] ‘conductor’. It is possible that the behavioral difference resides in syllable differences, where only tautosyllabic preceding consonants cause voicing and only nasals precede other consonants in a syllable, e.g., [ɛ.bɔ́ɔ́s.ta] vs. [ŋgoo.nʲi] ‘I helped’. There is no evidence for the syllabification of clusters such as in [e.bɔ́ɔ́s.ta], and appeal to syllabification patterns would not eliminate the need for something describing nasals—the implicit rule of syllabification relied on in a syllable-based account must still distinguish nasals from other consonants, since only nasals can be pre-consonantal in the onset.
We now summarize the input-output relations seen in hardening. A segment in one of the five sets of the first row (mnemonically the T class with up to four kinds of consonant) changes to the corresponding segment of the second row (the D class with a single consonant type). Place mnemonics are also provided.

That means that the rule modifies some features, and leaves others unchanged. It is clear that the rule neutralizes manner distinctions and does not affect place features. Within the place-characterized subsets {p, v, w, h, b}, {t, r, d}, {tʃ, dʒ}, {j̪, z} and {k, g}, additional features distinguish the individual members.
It facilitates the analysis of hardening to deal with nasal deletion. A nasal (the 1s subject prefix in (10)) deletes before /m, n, nʲ, n̪, ŋ, s/ (always), and optionally before /f, ʃ/.4

Nasal deletion applies first, in a more specific context. We characterise the trigger segments {m, n, n̪, nʲ, ŋ, s, ʃ, f} as having a feature S, which the remaining consonants lack. Because of the limited set of consonant clusters in Logoori, it is not clearly necessary to restrict the deleting consonant to one bearing S, but the trigger must be specified as having S, otherwise the nasal would delete in [m-bááji] ‘I visited’. The only word with non-nasal C plus S-consonant is ɪribóksi ‘box’, also attested as ribóógɪsi. This word could be excluded as an exception, the rule might be restricted to heteromorphemic clusters, or the target might be limited with a feature—S itself suffices, since nasals are in the class S. Other features internally distinguish the members of the set S. This leads to a simple Nasal Deletion rule. Since clusters like sn, sf do not exist in the language, no further restrictions are needed.

Hardening affects remaining NC sequences. The T→D alternation will, if possible, be expressed as spreading of a node from the triggering nasal (12a), or as deletion of A after a nasal (12b). The former implies that nasals have the property characteristic of segment class D, and the latter that D is characterized as lacking A.
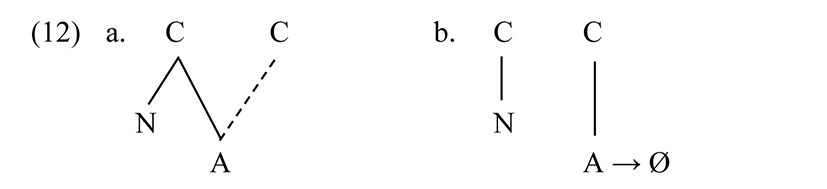
Since the subset {p, v, h, b} is composed of four manner subtypes, at least two additional features, dependents of A, are needed, giving rise to the specifications A, A + B, A + C and A + B + C.5
Under the spreading analysis, nasals and D consonants could be A + B + C: or they could be empty under A. In spreading A from the nasal, existing specifications of the target are lost in favor of A + B + C borne by the nasal, if that is the analysis of nasals. In the deletion analysis, and assuming a feature identifying nasals, D segments are unspecified for A and its dependents. The segments of the T class would be A plus combinations of B and C. We can delay deciding between these analyses and focus on the trigger.
The process is only demonstrably triggered by nasals, since only nasals appear before another consonant. Exceptions, which are loanwords, might be disposed of in the same way that we dealt with exceptions to S-deletion: restriction to heteromorphemic clusters, or the features of the target class. In this case, the number of such CC clusters is not trivial, so dismissing the data seems inappropriate.

sC clusters are particularly tolerated, whereas sequences of the type N + T are completely absent even in loans such as ɪɪndʒi ‘inch’, which evidence voicing. There is, therefore, reasonable evidence that only the nasal subset of S is positively identified as triggering hardening. How do we distinguish nasals from the fricative subset of segments within class S? Nasals are distinguished within the class defined by S as also having A.
We now have a basis for selecting the spreading analysis: we do not need an additional feature N. Spreading is simply spread of A.

To maintain deletion analysis (12b) and exclude (voiceless) stops and fricatives as triggers, an additional feature carried only by N must be specified in the rule. Simplicity thus favors the spreading account of hardening and the analysis of nasals versus fricatives as presence of A (for nasals) versus absence (for fricatives).
Given (14), {m, b} are identical in their specifications under A, and other arrangements of dependent of A describe {v, h, p}. At this point we have no evidence supporting one analysis of those distinctions over the other, but below we discuss a rule applying to /h/ but not /v, p, m, b/. If /h/ is specified as having all of {A, B, C} a rule applying to /h/ refers to presence of both B and C. This motivates an analysis of manner features as follows.
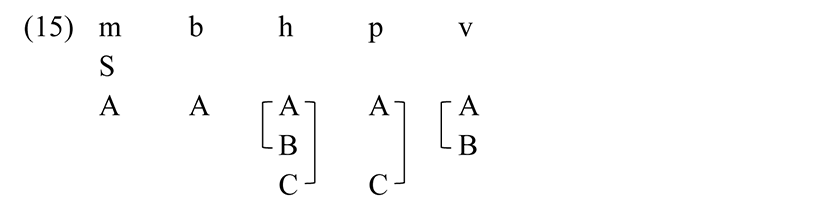
Labials exhibit the maximum set of manner contrasts. For other places of articulation, there is a nasal (/ŋ, n̪, n, nʲ/), a “voiced stop” segment (/g, z, d, dʒ/); for all but front consonants there is a voiceless stop (/k, t, tʃ/); and for front and alveolars there is an approximant (/j, r/). The following are therefore possible manner feature assignments for all of the consonants.

There is no phonological evidence that {v, r, j} are the same for manner features, nor that {p, t, tʃ, k} are the same. RSFP does not purport to guarantee a unique analysis of all feature assignments based on grammatical facts, thus it is possible that [j] is analyzed as {A, C} analogous to [p]. To the extent that the specific feature assignment of segments does not bear on the simplicity of the resulting grammar, features can be assigned at random to segments from the set motivated in the language, in order to maintain phonological distinctions.
We observed that [ʃ] and [f] have two behaviors, one where the consonant hardens (m-bʷaidɪtʃi, m-bʲaagari) and one where the nasal deletes (faidɪtʃi ‘I profited’, ʃaagari ‘I sharpened’). The existing analysis predicts deletion and not hardening, if /f, ʃ/ are specified with S. The solution to optional deletion vs. hardening is that /f, ʃ/ (and no other segments) optionally gain the feature S. That rule refers in part to the fact that these consonants have additional (vocalic) place properties, as seen in the hardened outputs [bʲ, bʷ]. Manner features are relevant, as shown by the lack of option for nasal deletion before consonants like /d, g, t, r/, cf. ndʲɛ́ɛ́n̪aa ‘I am toe-dancing’, ŋgʷɛ́ɛ́naa ‘I am walking proudly’, ndʷeetʃi ‘I hip-danced’, ndʷáánaa ‘I am fighting’: *dʲɛ́ɛ́n̪aa, *gʷɛ́ɛ́naa, *tʷeetʃi, *dʷáánaa.
We start identifying place features by grouping segments according to the output of hardening as in (9), where place is held constant. This establishes 5 place groupings, manifested in {b, d, z, dʒ, g}. We need four features to describe these—Labial (b), Alveolar (d), Front (z) and Velar (g). Alveopalatal (dʒ) reduces to a combination of Velar plus Front. There is also evidence for a node Place organizing all of the place features. A nasal is always homorganic with the following consonant in the onset, as observed in (3) with forms such as m-baataani ‘I hired’, n-dáándʊri ‘I tore’, n-záári ‘I sued’, ɲ-dʒáádʒi6 ‘I started’ and ŋ-gʊ́rí ‘I bought’. Each of the post-nasal consonants {b, d, z, dʒ, g} selects a corresponding nasal before it: {m, n, n, ɲ, ŋ} (though |ɲ|7 is really non-phonological). The features characterizing these classes reside as a group under Place, and are assigned to the nasal by (17).

Phonetic “places of articulation” are grammatically epiphenomenal, so the existence of 5 superficial place-types does not entail 5 distinct features. Some places may be combinations of features, and some places may be unspecified. Therefore we search for evidence for the phonological activity of each of the places of articulation. If a rule picks out labials excluding all else, Labial must be specified—it is a thing which rules refer to.
Indeed, Labial is referenced by a rule exclusively applying in the context of labials. The prefixes /mi/ ‘class 4’, /mʊ/ ‘class 3’ delete their vowel when the following consonant is a labial, likewise class 1 /mʊ/ deletes its vowel before a labial.

The deletion rule only applies to high vowels, not the low vowel of the class 6 prefix ama-.

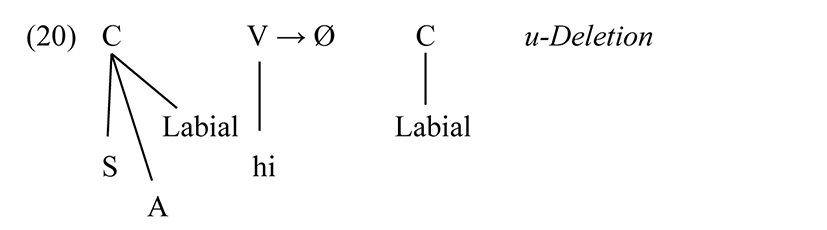
This rule deletes a high vowel after a labial nasal when the vowel is before a labial (the status of h is discussed later).
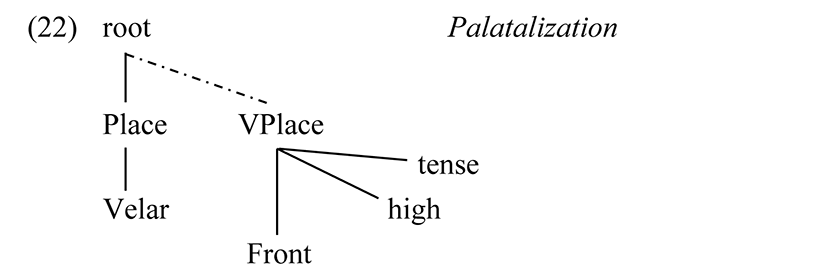
Palatalization, where a following tense high front vocoid [i, j] causes /k, g/ to become [tʃ, dʒ], illuminates place features. There is dialect variability, but the most general pattern is that /k, g/ become [tʃ, dʒ] before j derived from /ɪ/ by Glide Formation (below), and before the marker(s) /-i/ of the perfective, plural imperative, and the nominalization suffix. Palatalization does not apply at lexical level 1, the stem-derivational level, cf. [kodéékiza] ‘to make cook’, [kʊtáágiza] ‘to make plant’. Glide Formation only applies at level 2, so the triggering subset can be characterized as those sequences created at level 2. Examples with the three aforementioned suffixes /-i/ are as follows.

Features of the trigger spread, resulting in two sets of place features. “Velar” is motivated by the need to pick out the inputs (/k, g/), and to that is added the vowel place features “high front tense”. The result is, post-phonologically, an alveopalatal. Effectively, (22) creates [kʲ, gʲ], which are physically realized as |tʃ, dʒ| outside of the phonology. See discussion of secondary articulation below.
There is also a vowel deletion which optionally deletes high vowels preceded by /r/ if followed by any of {t, d, n, r, tʃ, dʒ, n̪, nʲ}. Subsequently, /r/ completely assimilates to the following C (geminate r is phonetically realized as |ll|). This is exemplified in (23) with infinitives having the object prefixes -rí- for class 5 and -rʊ́- for class 11.

This rule only applies to prefixes. The only consonants other than /r/ which precede high vowels in prefixes are /m, v, t, z, k, g/, none of which condition deletion. There is no reduction of rV before /z, s, ʃ, j/.
This gives evidence for a rule referring to {t, d, r, tʃ, dʒ, n, n̪, nʲ}, excluding other consonants. From this, we conclude that there is a common feature in these segments. That feature unifies Alveolar and Front as identified by the hardening alternation. The unity of alveolars and palatals is analogous to the unification of various lingual consonants with the feature Coronal in UFT: Front and Alveolar segments are specified as Coronal. How are Front consonants distinguished from Alveolar consonants, since {r, j̪}, {n, n̪} and {d, z} are distinct segments? Front segments are directly identified in rules (Palatalization, Front-tensing) but plain Alveolars are not exclusively referred to by any rule. Front is treated as Coronal dominating Front, and Alveolar as Coronal not dominating another feature.
As noted before, the 7 non-S labials {b, v, w, h, p, f, ʃ} cannot be entirely accounted for by combinations of the features A, B and C. The solution lies not in manner features, but in place specifications: ʃ and f are a labial with an additional vocalic specification, specifically /hʷ, hʲ/. After addressing vowel features, we consider how vowel and consonant features integrate.
The vowels of Logoori are [i, ɪ, e, ɛ, a, ɔ, o, ʊ, u]. All instances of [e, o] are followed by [i, u, e, o] in the next syllable and ultimately by [i] or [u]. The mid vowels [ɛ, ɔ] appear anywhere except before a tense vowel, and there are alternations between tense and lax mid vowels.

These facts indicate that underlying /i, u/ and derived [e, o] have a common feature [tense], which spreads from /i, u/ to a preceding mid vowel. It is not clear whether /ɪ, ʊ/ are immune to tensing before [i] and possibly [u]. In many tokens, there is a clearly higher vowel from /ɪ, ʊ/ before [i], but this raising is usually not found, and it is unclear whether the raised version of /ɪ, ʊ/ are identical to /i, u/. I therefore only exclude /a/ as a target of tensing harmony, and leave open the possibility of application of tensing harmony to high vowels. Mid vowels are identified with a feature “mid”. /a/ is treated as featurally empty, since it does not pattern with any other segments as a target or trigger for any featurally-based rule.

This divides the vowels into the tense set {i, u, e, o} and the non-tense set {ɪ, ʊ, ɛ, ɔ, a}. This alternation also establishes a relation between {e, o} and {ɛ, ɔ}, which is that {ɛ, e} and {ɔ, o} are the same except for the feature tense.
There is a widespread lowering harmony which lowers lax high vowels in a prefix to mid before a mid vowel.

Only lax vowels undergo lowering (no prefix contains /u/).

The fact that tense vowels do not undergo the rule raises a point about feature specifications in the theory. The feature [tense] spreads from a high or mid tense vowel, hence “tense” is a specified feature. Vowel lowering identifies the target as one which is lax. How is this expressed in a rule? There are three general approaches. An approach contrary to the premises of FP and RSFP is that some features are privative and others are binary ([+tense] vs. [–tense]). This substantially complicates the theory of representation and computation, and undermines the logic of feature learning, since not only would the child have to learn what the features are in the language (based on rules and representations having fixed formal properties), the child would also have to learn the syntax of individual features.
A second solution is to admit negative-existential references in rule statements, for example “when X is not associated to Y”. Such conditions on rules have been adopted in autosegmental phonology, for example “H tone spreads to a vowel which does not stand immediately before a H toned vowel”. The arguments for such conditions are, nevertheless, not compelling, see Odden (2021) for discussion. This is not an unsuperable complication of the theory, but it does complicate the theory, and the rationale behind RSFP is positing the fewest devices possible in UG.
The third solution is that there are two mutually exclusive features, tense and lax: [i, u, e, o] are tense, [ɪ, ʊ, ɛ, ɔ] are lax (there is no evidence that /a/ is either). This increases the complexity of Logoori grammar by adding a feature, but it is the underlying premise of RSFP that complexities belong in the grammars of the languages having them. Accordingly, Lowering Harmony is formalized as (29).
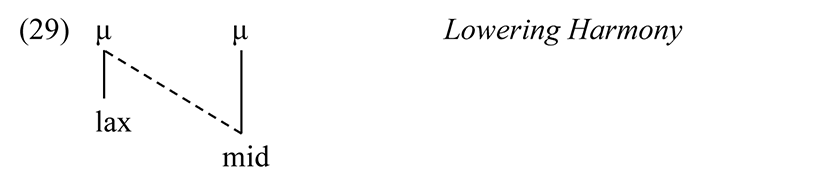
With respect to vowel height, we classify [i, u] as {tense}, [ɪ, ʊ] as {lax}, [e, o] as {tense, mid} and [ɛ, ɔ] as {lax, mid}—[a] is unspecified, indeed for all place features, since it is never specifically referenced by any rule. From these harmony alternations, we also see that {i, ɪ, e, ɛ} are the same except for the vowel height features, as are {u, ʊ, o, ɔ}. These sets are labeled Labial and Front, exploiting features used for consonants as well (plus, the feature Front is relevant for characterizing Palatalization triggers).
The surface distinction between [j] and [j̪] is predictable from phonological context. Underlyingly, there is one front glide, /j̪/, which becomes [j] before [i]. /n̪/ also becomes [nʲ] before [i]. Alternations such as the following motivate a rule of “front tensing”. There is also an alternation where /j̪, n̪/ become [j, nʲ] before the adjective suffix [u].
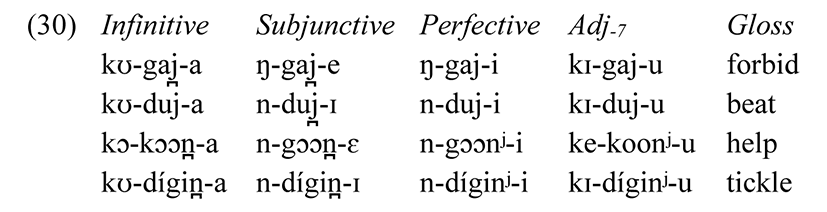
The crucial difference between /i,u/ which trigger this rule and /ɪ,ʊ/ which do not is that the trigger is a tense vowel.
Only high vowels trigger this alternation, cf. [kɔ-j̪ɔbɔj̪a] ‘to mumble’, [va-j̪oboji] ‘they mumbled’; [kɔ-j̪ɛɛra] ‘to sag’, [e-j̪eeri] ‘it sagged’. Since [e, o] always derive from /ɛ, ɔ/ via Tensing, simple rule ordering can handle the lack of front-raising in this context, and the height of the trigger need not be stipulated in the rule. The inference to draw from this alternation is that [j̪, n̪] are non-tense and [j, nʲ] are tense, and [tense] spreads from a following vowel. The following rule accounts for the distribution of [j̪, n̪] versus [j, nʲ].

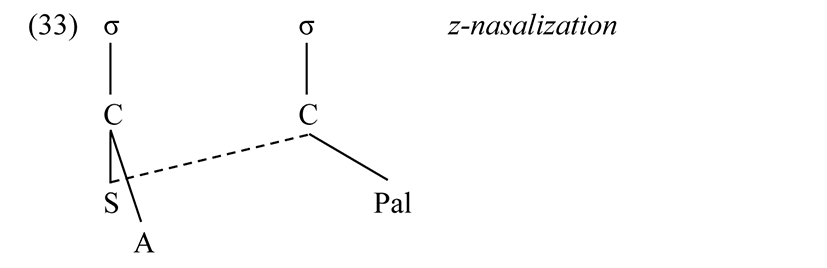
The fact that [j̪, n̪] behave analogously supports the decision to unify their places of articulation: they are Front, and the phonological Front consonants are {j, j̪, nʲ, n̪, z}, where {j, nʲ} are further specified as tense. There is additional support for this treatment, coming from a rule of z-nasalization. The causative suffix /iz/ is realized as [in̪] when the preceding consonant is a nasal. This follows from the analysis that [n̪] is the nasal at the place of articulation of [j̪, z].

The following rule nasalizes /z/ when a nasal precedes in the previous syllable.9
Glide Formation eliminates vowel sequences by merging a vowel with a following onsetless syllable: a glide appears in place of the vowel of the first vowel in the sequence (/a/ simply deletes). In the case of a prevocalic vowel-initial prefix, /ʊ/ becomes [w] and /ɪ/ becomes [j̪, j].10 This alternation demonstrates that {j, j̪; ɪ} and {w; ʊ} have the same place features—Front and Labial, respectively.

This transfer of place features from a syllable nucleus to the onset of the following syllable under syllable merger, in a fashion familiar from numerous autosegmental studies, e.g., Clements (1986)et seq. Our present concern is not with the theory of prosodic structure, so the rule will simply be expressed as follows.
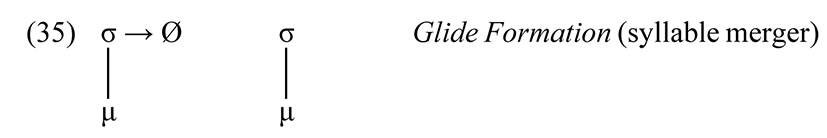
Via (35), the segmental content of /ʊ/ moves into the onset, and is interpreted phonetically as a glide (a vocoid not in the nucleus).
A consonant may also appear before a prefix vowel, in which case the vowel’s place features merge with those of the consonant, resulting in a secondarily-articulated consonant.

The result of syllable merger applied to a CV syllable is that the place features of V are transferred to the consonant. There are various plausible ways for place features to be organized within the segment. Three models of [kʷ] are given below.
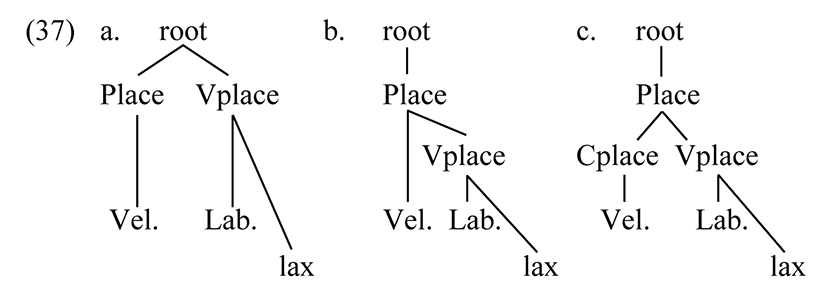
Theory (c) is more complex than (b), in positing an additional node. There being no advantage to such a node, (c) is ruled out. An empirical advantage of (b) is that it predicts that place assimilation in /N + gʲ/ assimilates secondary articulations of the following consonant, not just the primary articulation, giving |ɲdʒ| and not *|ŋdʒ|. This consequence is discussed in §5.
If alveopalatals are the phonetic interpretation of [kʲ, gʲ], it is correctly predicted that /kɪ, gɪ/ become [tʃ, dʒ] before a vowel.
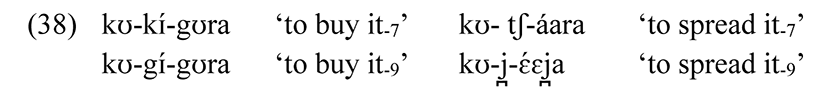
In light of this analysis of vocalic features of consonants, we can see that the path to understanding the phonology of [ʃ, f] is to analyze these segments as some labial—one which undergoes hardening—which also contains vocalic features. These segments are essentially [hʲ] and [hʷ], that is, the same manner features as /h/ but with Front and Labial as a secondary articulation. The plausible labial candidates in terms of manner features are /p, h, v/. We can rule out /v/ on the grounds that [vʷ, vʲ] are distinct segments from [f, ʃ], see [vʲɛɛrɛ́máa] ‘they-8 are floating’, [vʷɪɪnɪkáa] ‘it-14 is fermenting’. [pʷ, pʲ] are lacking, but [p] is extremely rare in any context. Phonologically speaking, phonetic ʃ, f are [hʲ, hʷ], and the pronunciation as |ʃ, f| may be a matter of how the output of phonology is implemented by the phonetic component of Logoori (see section 5).
Since in RSFP the feature analysis of segments that is learned is a consequence of the rules of the language, we scrutinize the logic of S-insertion to see what is required to state the rule. The rule must identify h and exclude /b, v, p/, which never trigger Nasal Deletion. Given /b, v, p, h/ and the feature A plus dependent {B, C}, some arrangement of A combined with any of {B, C} suffices to cover these segments. When a rule specifies just A, it refers to all 4 segments; when it specifies just B or C, it refers to two segments ({B, B + C} or {C, B + C}. Only a specification {B + C} identifies a single segment. Thus h is A dominating {B, C}. The segments which optionally gain S are those which are both B and C, and which bear a second place specification.
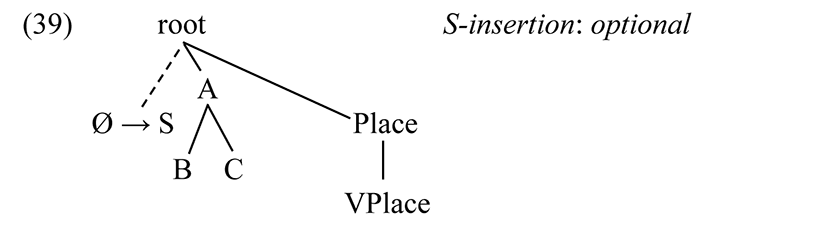
It may not be necessary to specify that the target is Labial, if no segments at other places of articulation have the specification {B, C}. Labial has the maximum number of manner distinctions, and no rules refer specifically to a class defined by B or C, therefore the specification {B, C} suffices to identify /h/. While the effect of the rule is directly visible post-nasally via the optional application of Nasal deletion, we cannot automatically conclude that (39) only applies after a nasal. As stated, [f, ʃ] have two feature analyses in free variation in all contexts, one with S and one without, but the phonetics does not overtly exploit that difference.
The final labial, which we have not yet fully analyzed, is [w]. What distinguishes [w] from [p, b, v, h, f, ʃ]? The latter two are distinguished by combining two place features. We can conclude that [w] does not have two place features (it is not a double-labial as [f] is), because when it hardens, it becomes [b] ([m-béédʒi] ‘I wagered’ from /w/) and not [bʷ] ([m-bʷaidɪtʃi] ‘I profited’ from /f/). The glide [w] often derives from an underlying vowel, for example [w-áámbʊkaa] ‘you are crossing’ from /ʊ-áámbʊkaa/, thus it has a V-place specification. Vowels also bear features for height, namely mid, tense and lax. I assume that non-alternating /w/ is likewise specified. It is not clear from the phonological evidence whether [w] is [lax] or [tense], so I arbitrarily assume that [w] is [lax]. Again, the data of the language only tells us that [w] has some (possibly null) specification of B and C in addition to [lax].
We can now summarize the feature analysis of Logoori segments. Five features under Vplace cover vowel distinctions: Front {i, ɪ, e, ɛ}, Labial {u, ʊ, o, ɔ}, Tense {i, e, u, o}, Lax {ɪ, ɛ, ʊ, ɔ} and Mid {e, ɛ, o, ɔ}. Consonants are distinguished by Labial {m, b, v, h, p, w}, Coronal {n, d, r, (s), t} plus the sub-feature Front {n̪, z, j̪}11, Velar {ŋ, g, k}, plus tense {nʲ, j} and lax {w, j̪}. Place features are also unified under a node Place, and a consonant may have two place specifications in the case of overtly secondarily-articulated consonants ([vʷ, vʲ]), as well as /hʲ, hʷ/ which are realized phonetically as |ʃ, f| and /kʲ, gʲ/ which are realized as |tʃ, dʒ|. Consonant manner is described with S assigned to {s, m, n, n̪, nʲ, ŋ}, optionally to {hʲ, hʷ}, and A (assigned to all consonants excluding /s/ and optionally hʲ, hʷ) with the latter dominating sub-features B, C. The exact assignment of B, C to segments is not uniquely determinable from the rule system, though we know that {m, n, n̪, nʲ, ŋ} and {b, d, dʒ, z, g} have the same values of B, C, and that [h] has both B, C.
5. Phonetic Interpretation
The SPE theory of features requires physically-based features because in that theory, the output of phonology is a complete specification of all language-specific details of an utterance, and is submitted only to to nonlinguistic universal articulatory processing (Chomsky & Halle 1968: 293-295). In contrast, RSFP (and other theories of representation) maintains a separate component of phonetic interpretation with a separate set of phonetic primitives. Somehow, the outputs of the phonological component of Logoori are physically realized, and perceived physical inputs are mapped onto surface phonological forms. Exactly how this happens has been a matter of debate in the history of generative grammar, and cannot be resolved here. The primary question is, what are the symbolic units required in the phonetic component, in order for it to perform its computations? Assuming some theory of phonological representation and computation, and the same for phonetics, the central question of interpreting phonological outputs is, does phonology get us only as close to physical outputs as is mandated by the theory, or does it get us as close as possible? Is aspiration in the phonology of English, or the post-phonology? This question is often elevated to the status of theoretical axiom, for example by defining phonology in terms of “contrast” which may then be defined in terms of minimal pairs, and adding a requirement to phonological UG that grammars cannot compute “non-contrastive segments”. FP rejects such arbitrary stipulations as necessary for computing phonological forms. RSFP takes it to be an open question whether English aspiration is in the phonology, or after the phonology.
The best-known symbolic theory of phonetics is Articulatory Phonology (Browman & Goldstein 1992), which posits a universal, physically-grounded set of properties (gestures) such as “lip aperture”, “tongue body constriction location”, “glottal aperture” along with quantized values for degree of constriction and location (“closed… narrow… wide”; “labial, dental, alveolar…”. Gestures have five timing landmarks, and gestures can be coordinated by reference to alignment of one landmark with another. One view of what phonetics does is convert such a representation into a series of numbers, thus phonetics turns categories into continua. This may involve specifying a target with some numeric value, and applying an interpolation function to get from one target to the next. It is an open question whether language-specific phonetic differences result from language-specific differences in the rules of implementation, or are they exclusively the result of language-specific differences in the initial representational state in the phonetics?
Without a clear picture of what the purported universal phonetic representational primes are, we can only speculate what the path for physically interpreting Logoori phonological outputs is. We can identify plausible theoretical issues regarding phonetic implementation, based on how phonological outputs of Logoori are interpreted. One point that must be underscored is that there is a connector between phonetics and phonology: an interface, which translates phonological representations into phonetic ones. So not only must we determine the formal nature of phonetic representations and computations, we must determine the formal nature of the interface (transducer) which changes one kind of representation into another.
There are competing theories of the phonetics-phonology interface. Hale et al. (2007) posit a linguistically invariant but contextually rich transduction of phonological representations to physical objects, with rules fronting [u] between coronals and backing [i] between velars, where systematic language-specific variation is generally the result of some phonological rule affecting universally-given features (or underspecification). On the other hand, Scheer (2014) sees transduction as being learned, but being a non-computational unit-to-unit translation. Aspiration in English would most likely be the result of a language-specific phonological rule in the Hale, Kissock & Reiss approach, and a language-specific post-phonological translation in Scheer’s approach. To this we must add the possibility (for theories that have a phonetic component) that the phonetic grammar of two languages might differ. Insofar as the Hale, Kissock & Reiss theory is based on universal innate features and invariant translation from phonology, which is exactly the opposite of the approach taken here, the reader can assume that RSFP operates in terms of a more Scheer-like learned transduction and language-specific phonetic computations. Post-phonological processing is not entirely arbitrary, since phonological outputs must be converted by possible transductions into phonetic objects, and phonetic processing qua mental computation has some formal nature. We cannot hope to cover the ground of the theoretical ways to accomplish post-phonological processing, but we can indicate some non-trivial issues for Logoori which might be covered by transduction and phonetic grammar itself.
An example is that the Front glide and nasal are realized as |j̪, n̪| or |j, nʲ| depending on whether they are specified as tense or lax as controlled by the following vowel. Since [z] is the “stop” version of /j̪/, we predict that there are tense and lax variants of [z] as a function of the following vowel. There is no perceptible difference beween the consonants of [vavarizɪ́] ‘they should count’ and [vavarízi] ‘(pl.) count them!’, as opposed to the very clear difference in [vadigin̪ɪ́] ‘they should tickle’ and [vadigínʲi] ‘(pl.) tickle them!’ or [vaduj̪ɪ́] ‘they should beat’ and [vadují] ‘(pl.) beat them!’. The uniformly alveolar realization of the phonological “palatal stop” might be the result of an interface rule translating the requisite feature structure into a phonetic object like “voiced alveolar fricative”: and then the fact that both the tense and lax version merge into alveolars could be the result of how the interface translation is stated. Or, it could be the result of a phonetic rule that eliminates the tense-lax distinction in stops. We cannot decide that matter here, lacking a fleshed-out theory of post-phonology. Similarly, we noted the possibility that /hʲ, hʷ/ are freely specified with S or without S in all contexts, but there is no phonetic sign of two such representations, therefore the interface or the rule system will be structured to converge on a uniform output.
In connection with competing theories of secondary articulation in (37), we noted that positing Place dominating primary and secondary place features better accounts for the realization of /ŋgʲ/ as |ɲdʒ| rather than *|ŋdʒ|, where the nasal is physically realized with the same place of articulation as the following consonant. If only the primary Velar value spreads by place assimilation to the nasal, it is puzzling that the nasal is not strictly velar, whereas if all place features spread to the nasal, the physical realization as an alveopalatal nasal—which is not an independent distinctive segment of the language—is an automatic consequence of having both sets of features being dominated by one node. It’s not that it is impossible to describe this fact in phonetic terms—one could assume additional interface or phonetic rules realizing phonological [ŋ] as |ɲ| before [gʲ] or an “alveopalatal”. The point is that positing a dominating node Place results in a simpler phonetics, and the child’s concern with formal simplicity is with the net simplicity of the entire grammar, not just that of the phonology.
In some cases, there is phonological evidence pointing in the direction of a phonological analysis of a potentially phonetic matter. We have seen evidence that /h/ phonologically behaves as a labial, at least with respect to the output of hardening. For the purposes of u-Deletion (20), [h] does not behave like a labial, see [ɪmihɪ́ga] (*[ɪm̩hɪ́ga]) ‘years’. This could theoretically be accounted for by complicating the u-deletion rule so that it applies before any labial except [h], but at least in the present rule-formalism framework, such an exclusion is unstateable, because there is no conjunction of features that refers to “labials that are not h”. The clear alternative is that Labial is deleted from /h/, after Hardening, so closer to the end of the phonology [h] is empty under the Place node (or lacks Place). This corresponds to the type of late-ordered phonological rule posited in an account of English which treats aspiration and flapping as phonological. In the case of Logoori h, we have direct evidence from phonological-class behavior that h is grouped with other labials for some processes, and separated from labials for others.
6. Conclusion
A major desideratum of certain branches of contemporary linguistic theory has been to retract as many as possible of the rich collection of nativist assumptions previously made in generative grammar, so that we can identify the features which must truly be part of the innate language faculty of humans. This paper is a contribution to the broader change of the central question of linguistics from “how much must be attributed to UG to account for language acquisition?” to “How little can be attributed to UG while still accounting for the variety of I-languages attained?” (Chomsky 2007). The alternative to claiming that properties of languages are genetically endowed is to say that they are learned based on exposure to language facts.
Not everything can be learned, for example a child does not “learn” which of the competing computational theories of language sound structure is “applicable” to a given language (OT, rule-based phonology, SPE theory, exemplar theory). The universal architecture of the language faculty is the basis for saying what is a possible grammar. In the context of said architecture having been established, and as shown in this paper, the child applies simple analogical reasoning to the primary linguistic data to discover that {p, t, k} behave a certain way, and that they have a relation to {b, d, g} in terms of the grammatical system of the language. Because phonological computations are a specific operation on structured features and similar representations, the child can infer sameness and difference of those features as a function of which segment is at stake, and how that segment patterns in the rule system.